Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 9 Ways to Improve Your Dataplex Auto Data Quality Scans

Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Google Cloud’s Dataplex is a data fabric tool that enables organizations to discover, manage, monitor, and govern their data across all of their data systems, including their data lakes, data warehouses, data lakehouses, and data marts.
With Dataplex, teams get lineage and visibility into their data management no matter where it’s housed, centralizing the security, governance, search and discovery across potentially distributed systems.
Dataplex works with your metadata. As you add new data sources to your data stores, Dataplex leverages the structured and unstructured metadata with built-in data quality checks to maintain integrity.
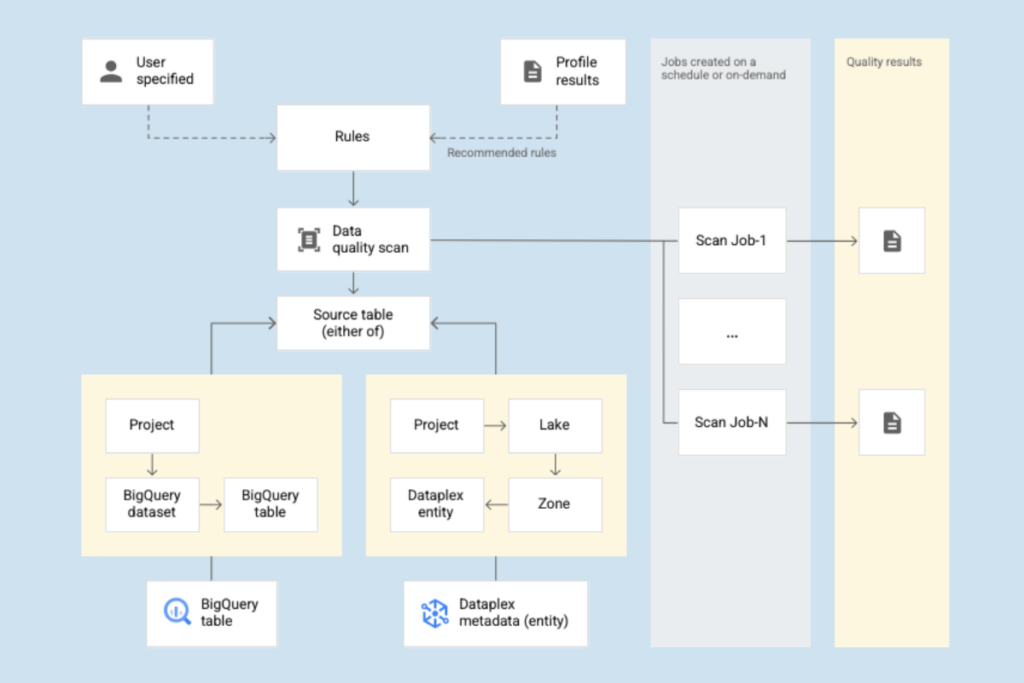
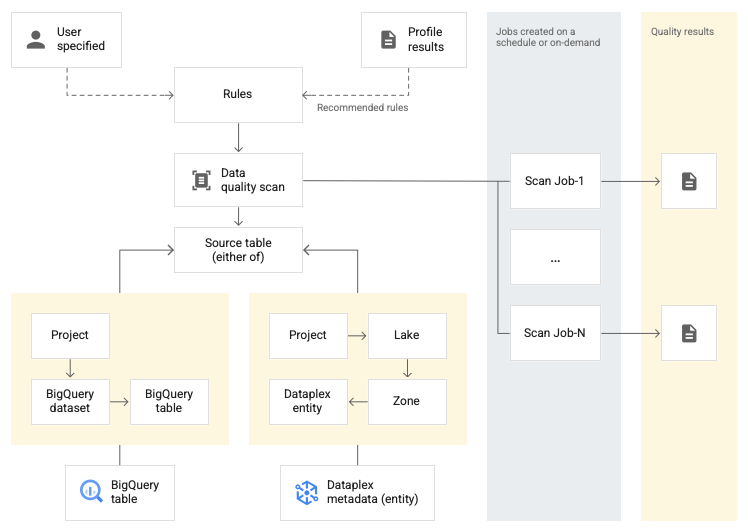
These data quality checks consist of the following steps:
- Rule definition: Choose between two pre-defined rules: row-level or aggregate
- Rule execution: Schedule data quality scans at an interval or on demand, and specify either full tables or incremental scope)
- Monitoring and alerting: Each [data_scan] log with the [data_scan_type] field set to DATA_QUALITY contains the data source, job execution details (creation time, start time, end time, and job state), the result (pass or fail), and the dimension level (pass or fail)
- Troubleshooting failures: There are a few limitations to be aware of, and when a rule fails, Dataplex runs a query that returns all of the columns of a table, not just the failed column
There are several ways to set up rules that will help you get the most out of your Dataplex data quality scans. Read on for 9 ways to improve your scans – and in turn, your data quality – across your data organization.
Table of Contents
1. Use Dataplex Data Profiling Recommendations
Start by leveraging Dataplex’s own data profiling rule recommendations to quickly identify common data quality issues and apply proven solutions.
Dataplex recommends creating data quality rules either by using their pre-defined rules as mentioned above – by row or by aggregate – or by creating our own custom SQL rules.
The predefined rule types include:
Row Level
- [RangeExpectation] (Range Check): Check if the value is between min and max.
- [NonNullExpectation] (Null check): Validate that column values are not NULL.
- [SetExpectation] (Set check): Check if the values in a column are one of the specified values in a set.
- [RegexExpectation] (Regular expression check): Check the values again a specified regular expression.
Aggregate Level
- [Uniqueness] (Uniqueness Check): Check if all the values in a column are unique.
- [StatisticRangeExpectation] (Statistic check): Check if the given statistical measure matches the range expectation.
2. Implement Custom SQL Rules
Dataplex offers support for several custom SQL rules for data quality checks as well. Crafting custom SQL rules can help your team cater data quality checks toward your unique data validation requirements.
Dataplex supports two custom rule types:
- Row condition: Defining a SQL expression in a where clause. The SQL expression should evaluate to true (pass) or false (fail) per row. Dataplex computes the percentage of rows that pass this expectation and compares that against the passing threshold percentage.
- Aggregate SQL expression: The rules are executed once per table. Provide a SQL expression that evaluates to boolean true (pass) or false (fail).

3. Optimize Rule Parameters
Fine-tune the parameters of your data quality rules, such as setting appropriate passing thresholds and enabling strict checks, to ensure high precision in identifying data issues.
For example, for a [RangeExpectation] (Range Check) rule, you’re required to define the passing threshold percentage and the mean, min, or max values. But, to make your rule even more precise, you might also specify the following rule-specific parameters:
- Enable strict min: If enabled, the rule check uses “>” instead of “>=”.
- Enable strict max: If enabled, the rule check uses “<” instead of “<=”.
- Enable ignore null: If enabled, null values are ignored in the rule check.
4. Employ Incremental and Sampled Scans for Efficiency
Choose between incremental data quality scans or scan on demand, either using the Google Cloud console or a third-party API that works with your data stack.
In addition, if you don’t want to scan your entire dataset, you can run a sample scan with Dataplex, like a percentage of your data, to reduce scan times and costs without significantly compromising on data quality insights.
5. Leverage Filtering to Narrow Down Data Scope
Apply filters to limit the data being scanned, focusing on the most relevant segments or time frames to improve scan efficiency and reduce costs. This can also help your team focus on newly added data.
For example, you might want to filter out data with a timestamp before a certain date so you can focus on a subset of data.
6. Aggregate the results of multiple data quality rules
When creating a data quality rule in Dataplex, you’re required to associate it with a dimension. These dimensions can help you aggregate the results of multiple rules when it comes to monitoring and alerting to issues in data quality.
Dataplex includes support for the following dimensions to aggregate the results of multiple data quality rules:
- Freshness
- Volume
- Completeness
- Validity
- Consistency
- Accuracy
- Uniqueness
7. Regularly Review and Update Data Quality Rules
Data quality is not a one-and-done strategy – it’s a constant process to ensure your data is trustworthy. Especially as your business scales, your data quality needs may evolve in scope, and that means making the necessary changes to your data quality rules accordingly.
Make sure you’re periodically reassessing your data quality rules and thresholds based on evolving data patterns and business needs to ensure they’re still relevant and effective.
8. Automate Monitoring and Alerting for Proactive Management
Set up automated monitoring and alerting based on scan results to quickly identify and address data quality issues, minimizing their impact.
For each data quality job, the log with data quality scan fields includes:
- Data source
- Job execution details, like creation time, start time, end time, and job state
- Result: pass or fail
- Dimension level: pass or fail
Every succeeded job includes configuration information, like rule name, rule type, evaluation type, and dimension, and result information, like pass or failure, total row count, passing row count, null row count, and evaluated row count.
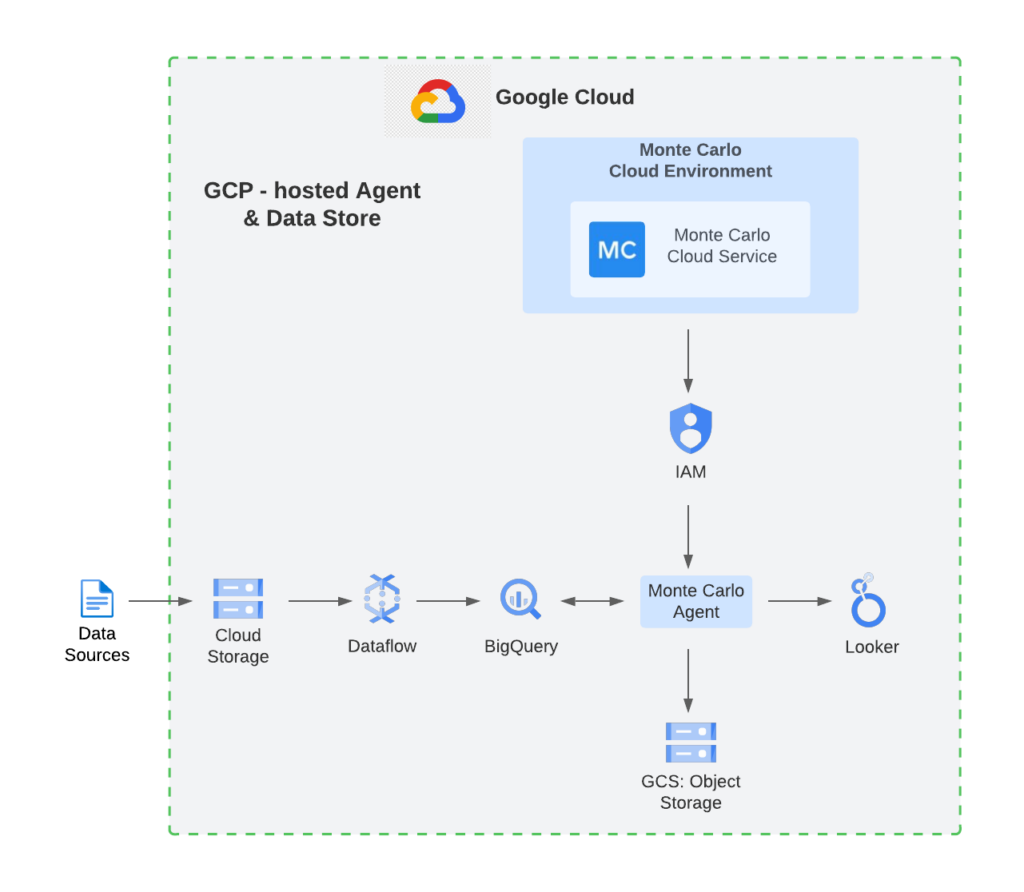
You can export these results to a BigQuery table, Looker dashboard, or other aggregated report to do a full analysis. You can then leverage a data observability tool, like Monte Carlo, to automatically parse the metadata and query logs in BigQuery to detect incidents and display end-to-end data lineage.
9. Benchmark and Share Best Practices Within Your Organization
Encourage knowledge sharing to leverage the collective experience to improve Dataplex auto data quality scans.
And, understanding the data starts with trusting the data. By getting more members of your data organization (and outside of the data team as well) closer to the data, the business can have a deeper understanding of the flow of information and how insights are collected.
Data observability tools, especially tools like Monte Carlo that include data lineage features, are key to helping data teams visualize and understand the end-to-end lifecycle of their data. They also streamline the monitoring and alerting process when data quality issues do arise, so the right stakeholders are notified and the resolution process can begin faster.
To learn more about how you can integrate your Google Cloud platform with Monte Carlo’s data observability platform, speak to our team.
Our promise: we will show you the product.
Read more posts.