Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Batch Processing vs Stream Processing: The Data Quality Edition


Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.
Why you need to prioritize data quality when considering batch processing vs stream processing.
It’s a debate as old as time (well, at least in data engineering): whether to leverage data in batches or to stream data in real-time.
Batch processing is the time-tested standard, and still a popular and common way for companies to ingest large amounts of data. But when organizations want to gain real-time insights, batch processing falls short.
That’s where stream processing fills the gap. It’s a game-changer to have access to data in real-time, and can lead to an increased return on investment for products and services that rely on data to be constantly updated.
That is, until the quality of data is impacted, and teams start using inaccurate data to drive decision-making. Because when data is streamed in real-time, the margin for error increases, with detrimental effects to the business.
For instance, credit card companies use stream processing to monitor credit card transactions in real-time to detect anomalies in their customers’ spending habits—allowing them to detect fraudulent purchases before customers realize anything’s wrong. If the data isn’t accurate and up-to-date, fraud detection can be delayed or missed altogether.
As another example, marketing teams position ads based on user behavior, using data that flows in real-time between a brand’s products, CRMs, and advertising platforms. One small schema change to an API can lead to erroneous data, causing companies to overspend, miss out on potential revenue, or serve irrelevant ads that create a poor user experience.
These scenarios just scratch the surface of what’s possible when bad data powers your perfectly good pipelines.
So, what’s the answer to batch processing vs stream processing? How do you solve for data quality with stream processing?
The old way: data quality for stream processing
Traditionally, data quality was enforced through testing: you were ingesting data in batches and would expect the data to arrive in the interval that you deemed necessary (i.e., every 12 hours or every 24 hours). Your team would write tests based on their assumptions about the data, covering some but not all of their bases.
A new error in data quality would arise, and engineers would rush to conduct root cause analysis before the issue affected downstream tables and users. Data engineers would eventually fix the problem and write a test to prevent it from happening again.
And as the modern data ecosystem becomes increasingly complex over the last decade—with companies ingesting anywhere from dozens to hundreds of internal and external data sources—traditional methods of processing and testing began to look more outdated. Testing was hard to scale and, as we found after talking to hundreds of data teams, only covered about 20 percent of possible data quality issues – your known unknowns.
In the mid-2010s, when organizations began ingesting data in real time with Amazon Kinesis, Apache Kafka, Spark Streaming, and other tools, they followed this same approach. While this move to real-time insights was great for business, it opened up a whole new can of worms for dealing with data quality and the batch processing vs stream processing debate.
If ensuring reliability for batch data is difficult, imagine running and scaling tests for data that evolves by the minute – or second! Missing, inaccurate, or late fields can have a detrimental impact on downstream systems, and without a way to catch data issues in real time, the effects can magnify across the business.
While traditional data quality frameworks such as unit testing, functional testing, and integration testing might cover the bare bones, they cannot scale alongside data sets that are hard to predict – and evolving in real time. In order to ensure that the data feeding these real-time use cases is reliable, data teams need to rethink their approach to data quality when dealing with stream processing.
A new approach to data quality for stream processing
To achieve the gold standard of streaming high-quality data at a high velocity, some of the best data teams apply data observability.
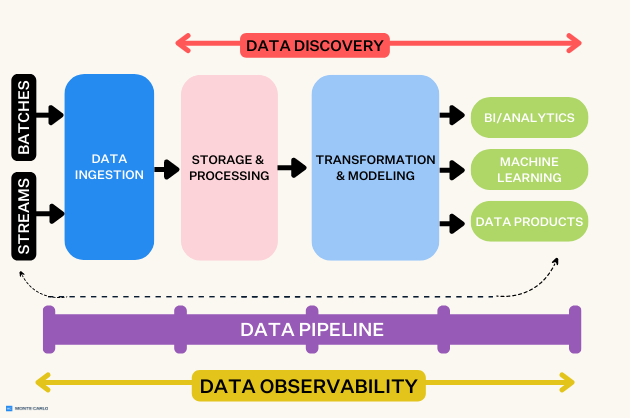
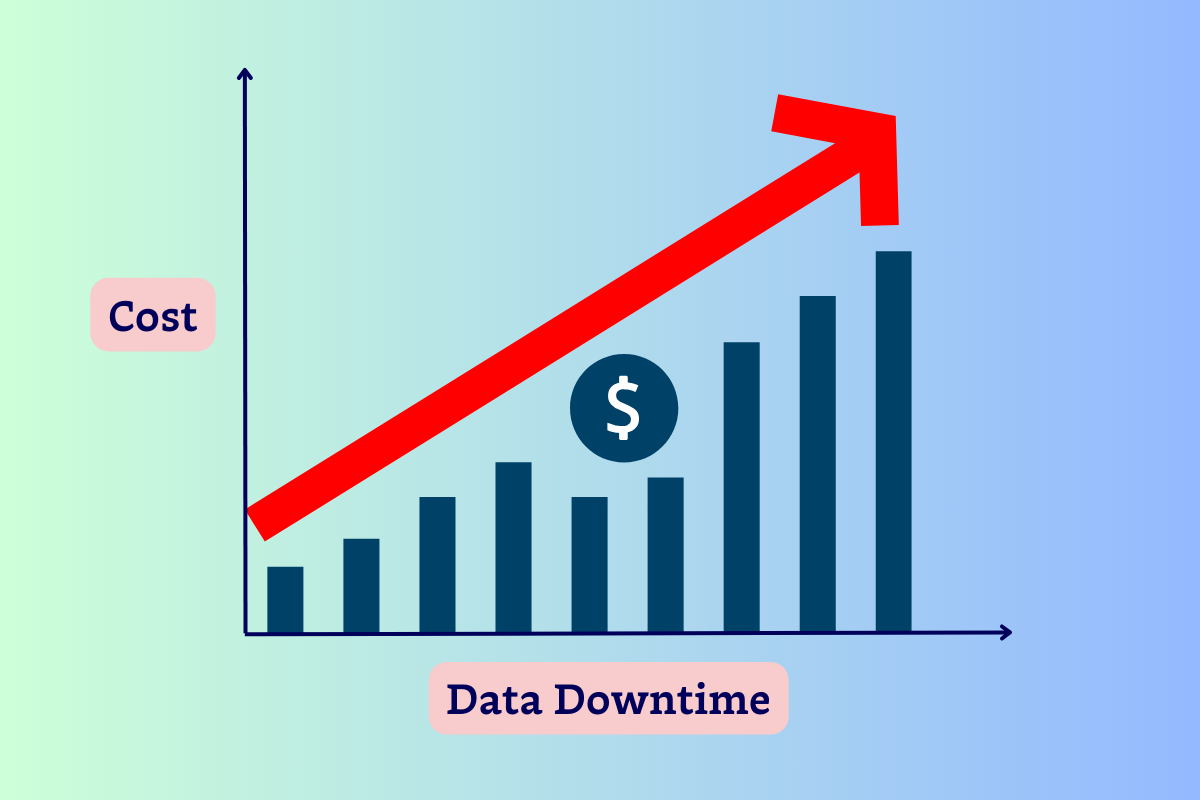
Data observability is an organization’s ability to fully understand the health of the data in their ecosystem. It works by applying DevOps Observability best practices to eliminate data downtime through automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues, leading to healthier pipelines, more productive teams, and happier customers.
Data observability breaks down into its own five pillars: freshness, distribution, volume, schema, and lineage. When put together, these five components provide valuable insight into the quality and reliability of your data.

So how can you apply the five pillars of data observability when stream processing data?
- Freshness: Freshness seeks to understand how up-to-date your tables are, as well as the cadence at which they’re updated. This is essential for stream processing, as the data needs to be ready and reliable in real-time. If not, poor decisions can be made, and stale data becomes a waste of time and money. Data observability helps your data team understand data freshness, giving you insight into how up-to-date your data is that you are streaming.
- Distribution: Distribution measures whether the data is within an accepted range. In terms of dealing with data from streaming, this is crucial–one anomaly is too many in most business use cases, and can lead to distrust in data from stakeholders. With data observability, data teams gain visibility into anomalies and can stop them from working their way downstream.
- Volume: Volume refers to the completeness of your data tables and offers insight into the health of your data sources. If you are stream processing data and suddenly 10,000 rows turns into 100,000, you know something is wrong. Through data observability, data teams can stay informed about any unexpected volume changes.
- Schema: Schema refers to changes in the organization of your data and is often an indicator of broken data. With stream processing, since you’re ingesting data from third-party sources that live outside your ecosystem, data observability alerts you to any unexpected schema changes—giving your data team a greater understanding of the health of your incoming data.
- Lineage: When data breaks, the first question is always “where?” Data lineage provides the answer by telling you which upstream sources and downstream ingestors were impacted, which teams are generating the data, and who is accessing it. By applying data observability, data teams can understand how their stream processing data flows throughout their ecosystem, leading to faster root cause and impact analysis when responding to data incidents.
Data observability incorporates all five pillars across your data ecosystem, from ingestion to analyzing, making it a must-have layer of the modern data stack. With the sheer velocity and complexity of data entering your ecosystem during stream processing, observability helps ensure high-quality data powers trustworthy decision-making and better data products.
The future of data quality, in real time
With stream processing comes great responsibility. While there is no one-size-fits-all answer for the batch processing vs stream processing debate, data quality should still be a priority rather than an afterthought.
Dealing with inaccurate data is detrimental for data engineers and business stakeholders. It wastes engineering time, costs your organization money, and erodes trust in data. Regardless of whether your company decides to leverage stream processing, make sure you have the right framework in place to manage data quality.
Stream or not, your data isn’t worth much if you can’t trust it.
Interested in learning more about data observability for real-time data? Curious about batch processing vs stream processing? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.