Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 9 Best Practices To Maintain Data Integrity Fit For The Cloud Era


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Data integrity is an old school term that predates the invention of the personal computer. It was used prominently, for example, in FDA regulations governing the pharmaceutical industry in the 1960s.
While that doesn’t make it an unhelpful concept, it does mean that many of the definitions and best practices you will find online today are hopelessly outdated.
Sure, some organizations (maybe even yours) still have on-premise servers, but the amount of critical workloads stored on that type of hardware dwindles precipitously by the day.
The data is of course still on hardware somewhere–likely in a rural datacenter within the cloud instance of some cloud giant–but the physical resilience of it is no longer the day-to-day concern for any data professional operating a modern data stack. In BigQuery, we trust.
So that best practice to “prevent your tape backup from corrupting” is not quite as relevant as it was a decade ago. Same with encrypting your data, which all major data clouds do by default.
Before we dive into data integrity best practices, we should start by talking about the traditional definition of data integrity, as well as a more modern interpretation.
What is data integrity, really?
Traditionally, data integrity refers to both the physical and logical integrity of the data. In other words, are both the hardware and digital systems fit to ensure its accessibility, security, and accuracy?
You may also see references to other characteristics of integrity such as completeness, accuracy, consistency, safety, validity, or quality.
However, not only has the physical integrity component become less relevant, but oftentimes you will hear these terms used interchangeably on calls with engineering professionals or see them mixed around in blogs written by well-meaning marketers.
I’d argue a more modern, high-level interpretation of data integrity is to take that list of characteristics and boil them down to the umbrella terms of “data quality + data governance = data integrity.” In other words:
Data integrity is the process of ensuring data is fit for the task at hand and available to only those who should have access.
Now with a high-level definition established, let’s get a bit more granular and look at 10 best practices for data integrity within a cloud architecture and modern data stack. The first 5 focused on data quality and the next 5 focused on data governance.
1. Monitor the data AND data pipelines
Data pipelines break all the time for a near infinite amount of reasons. You can’t create a test for every way data can break, and if you could, it would be impossible to consistently scale across all of your pipelines.
Additionally, even if the systems, code, and interdependencies within a data pipeline are all functioning properly the data itself flowing through them could be garbage.
Ideally, anyone who creates or updates data should ensure that the data they modify is complete, correct, accurate, and relevant. From manual data encoding up to the software engineering team that created the system used by the customers, there should be data quality checks even before the data lands in the data warehouse.
However, we all know this won’t happen 100% of the time and that’s where data monitoring comes in. Data observability solutions like Monte Carlo use machine learning to automatically monitor for broken data pipelines and data anomalies so data engineering teams can resolve these issues rapidly.
By identifying issues with data freshness, volume, schema, and overall quality, data observability solutions can help ensure entity integrity. In other words that data isn’t duplicated or there aren’t abnormally high levels of NULL fields.
2. Operationalize your root cause analysis process
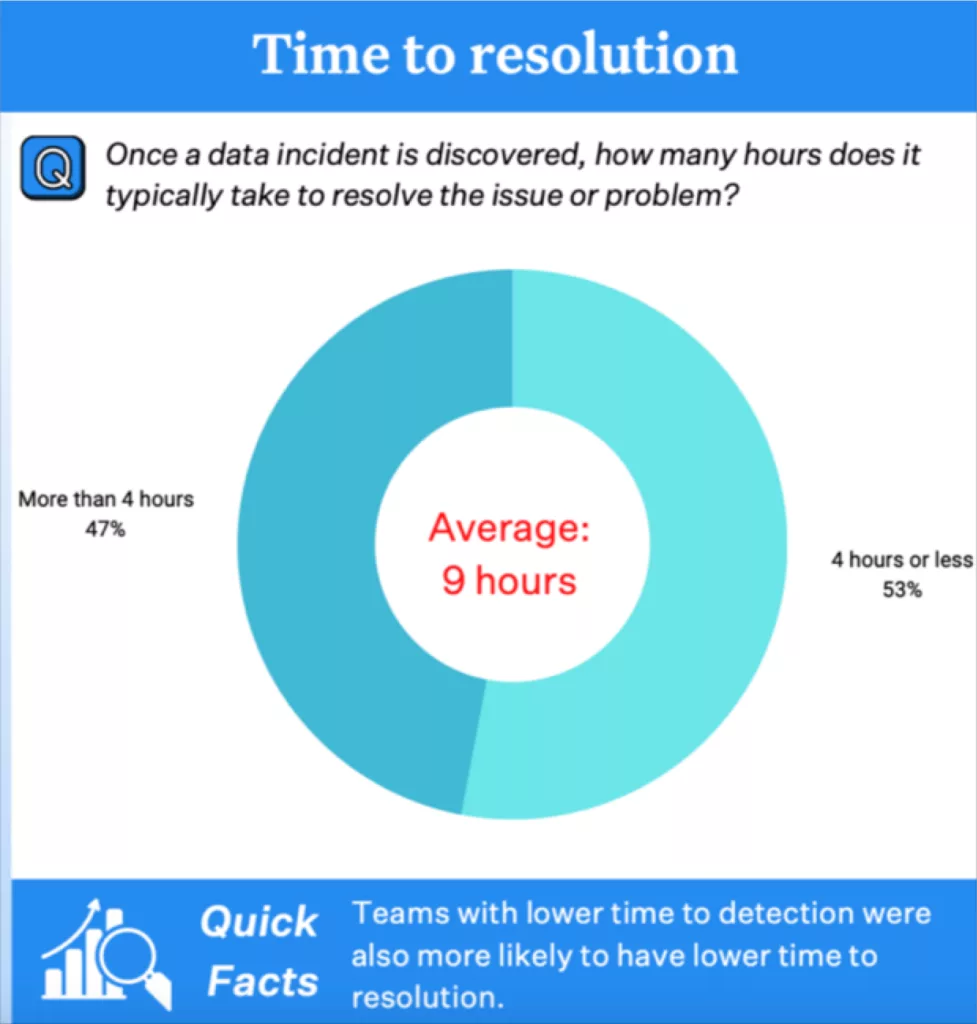
Once the incident has been detected, a member of the data team will need to determine and fix its root cause. A 2022 survey by Wakefield Research of more than 300 data professionals showed the average time to resolution for each incident was 9 hours!
Data observability solutions have features such as query change detection, segmentation analysis, and more that can help accelerate data incident resolution. It is also important to have clear lines of ownership in place as well as standard operating procedures for triaging and backfilling incorrect data.
3. Don’t leave data modeling behind
Our introduction was a bit critical of legacy best practices for data integrity, but data modeling is a technique that should never go out of style. Data models such as Kimball, Inmon, or Data Vault were critical for on-premises databases to ensure optimal performance, and are critical today to ensure referential integrity, in other words that the relationships between different data are correct.
4. Understand data dependencies

Speaking of referential integrity, automatic data lineage is an essential data integrity best practice for modern data stacks. Tables rarely contain the root cause of their own corruption. Data engineers need to quickly trace issues to the most upstream table to identify the root cause of an incident or understand provenance, while also needing to understand what tables and dashboards consume the potentially corrupted data downstream.
5. Treat data as a product. Enforce schemas and establish SLAs
Domain integrity refers to the organization and format of the data, in other words the schema. Treating data as a product is a process that involves gathering requirements and data consumer needs upfront and then enforcing that schema through either data testing, data contracts, data observability or all of the above.
The data product should also have an agreed upon service level agreement (SLA) dictating the level of reliability and freshness data consumers can expect.
6. Maintain shared understanding
Maintaining a shared understanding or semantic meaning of the data is a critical best practices for maintaining data integrity.
This can be done by maintaining a semantic layer as can be found in tools such as LookML or dbt. A semantic layer essentially definesand bundles the components of key metrics so they are used consistently across the organization.
Having a data catalog and standard data definitions can also help maintain proper governance and data integrity. With a centralized data catalog system in place, searching for data definitions or data products is much easier.
And last but not least, every data engineer’s least favorite task…documentation. Without it, you are reinventing the wheel and asking for sprawl.
7. Have robust backup systems in place
While data teams can trust that Google, AWS, and Microsoft probably have a better disaster recovery or hardware failover process in place for physical integrity, assuming they automatically backup your data is not a good idea.
Most service providers will provide some level of backup or retention, but it may not be at the level required by external regulations or internal policies. You should also be clear on the difference between backup (a separate copy of the data in another instance) vs retention (policies that prevent deletion or the ability to restore data within a certain window).
For example, Snowflake TimeTravel is a wonderful retention feature, but it should not be confused for backup. In a similar manner, Microsoft 365 will retain deleted SharePoint files for up to 93 days, but after that it’s gone.
8. Classify/tag your data and PII
Data regulations seem to be the only thing that are growing as fast as data is being generated. Organizations now need to adhere to international regulations like GDPR and even regional regulations like CCPA.
Most of these regulations concern the handling and access of personally identifiable information or PII. However, you can’t manage what you can’t see.
Having accurate object tagging in place makes it much easier to identify and monitor higher-risk data, and for governance teams to implement additional security measures like dynamic data masking or row-level access restrictions.
Snowflake object tagging allows data engineers and governance leads to track sensitive data for compliance, discovery, protection, and resource usage. Our customers in particular find this feature useful for tagging personally identifiable information (PII) data. For example, tagging a column with phone numbers as PII = “Phone Number.” Other helpful governance features include Dynamic Data Masking and Row Access Policies.
9. Create and review your access policies
Governing the access to dozens or even hundreds of data products across a complex data mesh structure isn’t easy. However, it can be done using a combination of services as long as you tag and maintain proper data hygiene. This should include regular reviews of access policies as people move within the organization, their levels of authorization may no longer be appropriate.
Interested in how data observability can improve your data integrity? Schedule time to talk to us in the form below!
Our promise: we will show you the product.
Read more posts.