 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is a Data Microservice Architecture?

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Microservices are small but powerful blocks within the data engineering ecosystem that orchestrate the movement and transformation of data. When multiple microservices are involved in manipulating the data, an architecture comes into play. This architecture is called a data microservice architecture.
Example of a Data Microservices Architecture
A hypothetical contemporary scenario is you’re a data engineer that needs to move and transform data from production databases (i.e. AWS RDS), third-party CDPs (i.e. Segment), and ad networks (i.e. Google Ads). You’d use a microservices architecture like the following:
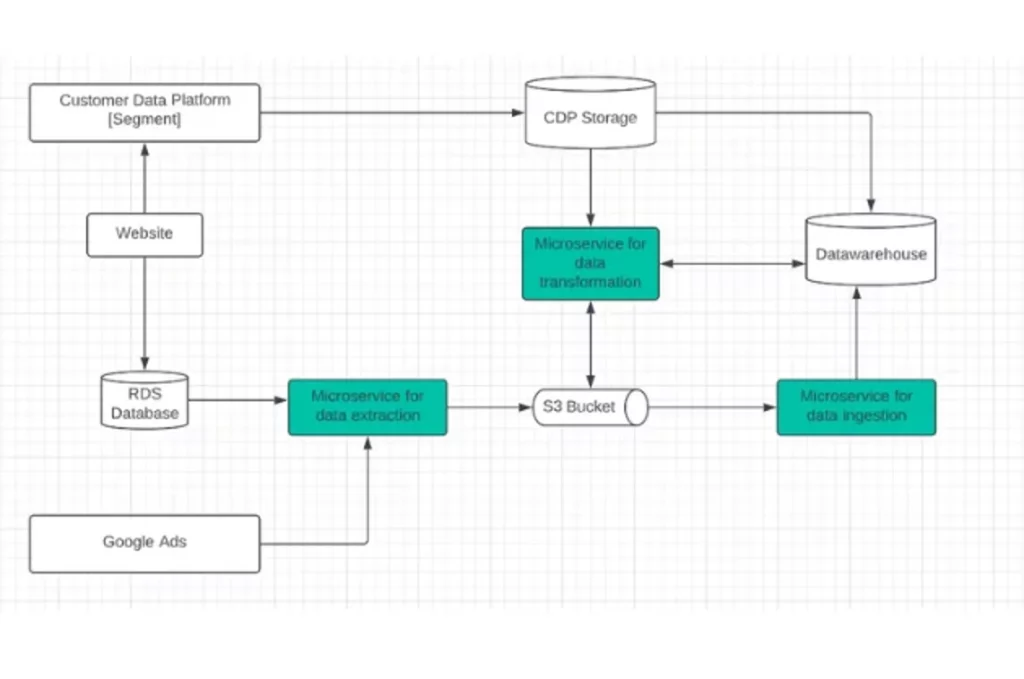
The microservices within the above data application are loosely coupled. For instance, an increase in ad impressions will not necessarily increase the transformation microservice’s throughput. Due to the need-based elasticity of microservices, cost and power exponentially decreases.
On the other hand, in monolith architectures, a throughput increase in one component will automatically increase the throughput of all components even if there is no need, drastically increasing the overall cost and consumption of resources.
Why the Loosely Coupled Nature of Microservices is So Great
- Within a massive code base, you can surgically modify a microservice without impacting the entire system.
- An erroneous microservice will not necessarily bring down the entire system. It would only impact a specific area.
- One microservice’s development, deployment, and continuous integration does not affect nor impact neighboring microservices or the entire ecosystem.
- Logs are captured for an individual microservice vs. an entire ecosystem. This reduces debugging time.
- Even if a bunch of microservices are sequentially connected they all can still run on different programming languages and logic to achieve the same overarching goal.
- One microservice ideally addresses one core functionality to achieve a service-oriented architecture, which is one the best methodologies when it comes to building data applications.
Communication plays a vital role in the microservice architecture. Popular methods of communication between microservices are:
- API requests
- SQS notifications
- SNS notifications
- On Insert, Delete, Update, etc.
Depending on the type of task that needs to be executed, any of the above communication methods can be implemented. If a task needs to be triggered based on a file drop on an S3 bucket, an SQS notification could be used. If migration of data has to kick start when a new row is inserted into RDS, on Insert trigger can be implemented.
Microservices vs. Monolithic Architecture
Before cloud services and microservices came into play most applications were built using a monolithic architecture. In a typical monolithic architecture, all components operate as one single unit. A standard monolithic architecture looks like the following:
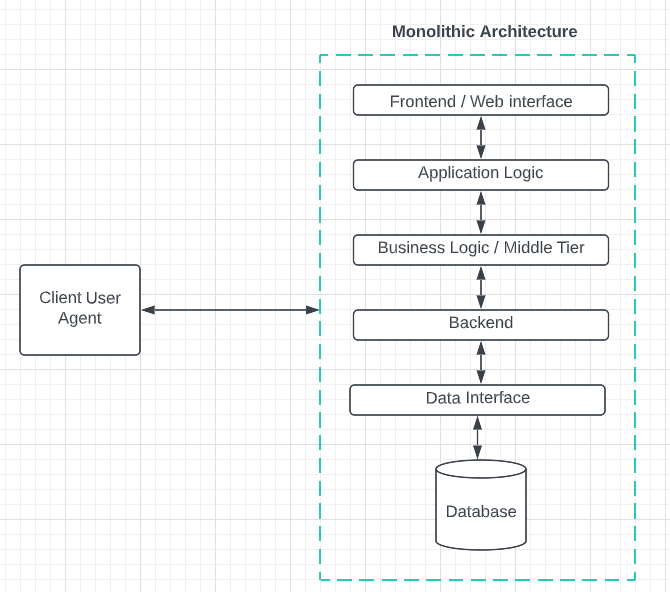
The advantages of a monolithic architecture are:
- Single-page web applications can be built in no time
- Performing end-to-end testing is easy given that the architecture has a single codebase
- More secure because there is only one entry point to the system
- They’re a viable architecture for proof of concepts, startups that are seeking funding, etc.
However, since monolithic architectures are tightly coupled, this results in several downsides:
- In order to make a minor change to the backend component of the architecture, the entire system needs to be restructured/revisited
- Deployment time proportionally increases along with new feature requests
- Even after a minor change to the codebase, a thorough inside-out regression testing needs to be done before the code is deployed in production
These pros and cons between data microservices and monolithic architecture can be summarized in the table below.
| Microservices | Monolithic Architecture | |
Scalability | Easy to scale until a certain point | Complexity proportionally increases while scaling up |
Easy of deployment | Turn key deployment; easy to execute | Easy for smaller applications but strenuous for bigger applications |
Maintenance | Cloud microservices are easy to maintain | Very hard for bigger applications |
Reliability | Uptime of more than 99% | Uptime is not guaranteed |
Fault tolerance | Very High | Unstable for bigger applications |
Performance | Cannot match with monolithic architecture’s performance | Very high if the application is orchestrated correctly |
Technology flexibility | Very high | Tightly coupled; highly inflexible |
Testability | Involves minimal effort | Complex process |
Continuous Deployment | Yes | No |
Continuous Integration | Yes | No |
Summary
Microservice frameworks are not a silver bullet solution to monolithic architectural issues. Microservices may be exceptionally great at data migration, transformation, enrichment, streaming, reporting, etc. to name a few. Yet, a monolithic architecture is great at scaling single-page web applications as it’s secure by nature. In short, there is an overlap between both of these architectures. Therefore, depending on the task, functionality, requirement, and other circumstances you may prefer one over the other.
⚠️ Don’t Deploy Data Microservices without Data Observability⚠️
When a chain of microservices are deployed to orchestrate data movement, a data observability platform becomes necessary in order to frequently check data for reliability as the nature of microservices requires successful handoff between each point in the chain to ensure data integrity:
-Monitoring and reporting on data downtime
-Unexpected schema changes
-Proper data governance is put in place before the data is shared in a decentralized manner
-Raise alerts: when historical patterns are not followed, when there is a very large or small influx of data, when upstream/downstream lineage changes
Learn more about Monte Carlo and schedule time using the form below!
Our promise: we will show you the product.
Read more posts.





