Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Snowflake Observability and 4 Reasons Data Teams Should Invest In It


Matt Sulkis
Matt is the head of partnerships at Monte Carlo.
Adopting a cloud data warehouse like Snowflake is an important investment for any organization that wants to get the most value out of their data.
The Forrester’s Total Economic Impact of Snowflake report uncovered a customer ROI of 612% with total benefits of more than $21 million across three years. ?
This immediate value is just scratching the surface. Most data teams, especially those early in their Snowflake journey, have yet to fully unlock full potential and value from this key investment.
If modern data warehouses like Snowflake are the data-driven engine powering valuable insights and efficiencies at your organization, then data observability solutions like Monte Carlo are the nitrous oxide accelerant. We believe every data team needs Snowflake observability.
Data observability is an organization’s ability to fully understand the health of the data in their systems and eliminate data downtime. Data observability tools use automated monitoring, alerting, and lineage to identify and evaluate data quality and discoverability issues.
In this post we’ll cover four ways Snowflake observability can optimize your investment in the Data Cloud:
- Increasing data engineering capacity
- Reducing data downtime
- Optimizing Snowflake migration and management
- Data trust and increasing Snowflake adoption
- Snowflake observability is essential
Increasing data engineering capacity
You have just migrated to the Snowflake data cloud and are now seeing first hand the power of hyperscale compute and data storage. You feel like the world is your oyster and the possibilities for how your data team can add value to the business is virtually infinite.
What should you do next? Set up more advanced machine learning models? Move toward a data mesh like domain-first team structure? Develop an external data product?
You eagerly rub your hands together, look to your handpicked data engineering team…and realize no one has bandwidth for any of these initiatives. They are all scrambling to fix the latest crop of data incidents.
You just bought a Ferrari and it’s stuck in the garage.

Forrester calculates data quality issues take up around 40% of a data professional’s time and recent Monte Carlo commissioned surveys have validated that finding.
Our own product data, which has accessed hundreds of data stacks end-to-end, has revealed the average organization will experience one data incident per year for every 15 tables in their environment. That adds up fast when you consider the best, most well equipped teams may identify and resolve an issue in 8 hours (and most take considerably longer).
What would you do if you suddenly had 40% extra data engineering capacity? What would your team build if they spent more time innovating and less time fixing?
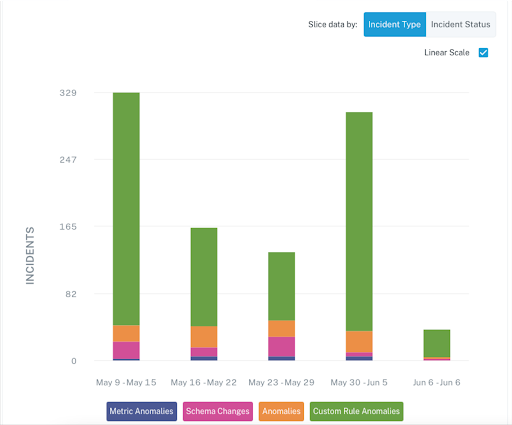
Data observability solutions leverage machine learning powered monitors to immediately alert teams to data issues reducing time to detection from hours or days to seconds.
Field-level data lineage automatically maps how data assets are connected, revealing the “blast” radius of the incident and pinpointing where the issue has occurred for dramatically lower time to resolution.
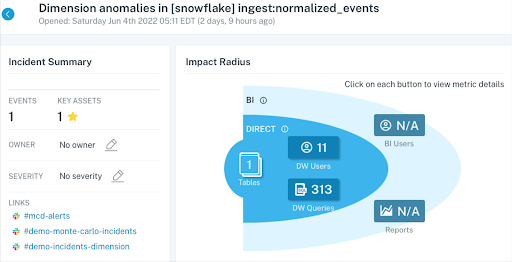
For example, the Optoro data engineering team leverages a Snowflake warehouse and estimates using Monte Carlo saves them at least four hours per engineer, per week, on support tickets to investigate bad data. With a data engineering team of 11+ members, this totals to 44 hours each week.
Reducing data downtime
And of course, the other benefit to suffering from fewer data incidents and resolving them more quickly is less overall data downtime. This data quality metric refers to the periods of time when when your data is partial, erroneous, missing or otherwise inaccurate.
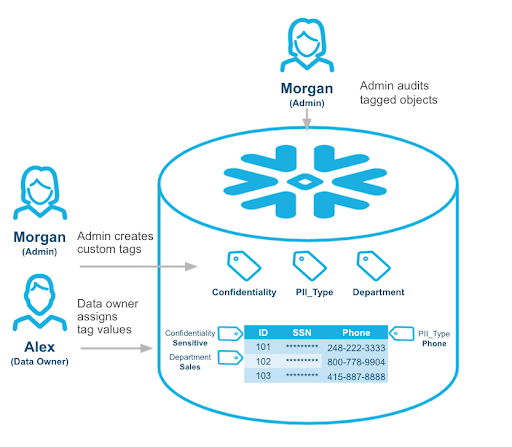
Snowflake supports some native features to improve data quality, but the unfortunate truth is data quality can be compromised in countless ways across all components of the modern data stack. This is why you need Snowflake observability.
Schema changes can corrupt downstream data products. APIs can break and halt the flow of important data into your warehouse. Data can be stale or duplicative.
You can have the greatest data cloud infrastructure in the world, but if bad data gets into your good pipelines, it won’t matter.
Data downtime is expensive. Gartner estimates poor data quality costs organizations an average $12.9 million every year. This could include everything from having your data analysts, data scientists and other data consumers twiddling their thumbs waiting for issues to be resolved to decisions being made based on guts rather than dashboards.
The biggest cost of course might be the loss of data trust and faith in your data team.
Data observability solutions are designed to greatly reduce data downtime. For example, digital advertising platform Choozle reduced its data downtime 88% by leveraging Monte Carlo and Snowflake. Choozle Chief Customer Officer Adam Woods said:
Snowflake gave us the ability to have all of the information available to our users. For example, we could show campaign performance across the top 20 zip codes and now advertisers can access data across all 30,000 zip codes in the US if they want it…
…I love that with Snowflake and Monte Carlo my data stack is always up-to-date and I never have to apply a patch. We are able to reinvest the time developers and database analysts would have spent worrying about updates and infrastructure into building exceptional customer experiences…
…I can’t imagine a situation where I would fire up Snowflake and not put Monte Carlo on top of it.
Optimizing Snowflake migration and management
We’ve previously covered how data observability solutions can help you migrate to Snowflake like a boss, but to summarize:
- When moving from a partition/index to cluster model be sure to document and analyze current data schema and lineage to select appropriate cluster keys as needed. Data observability solutions capability to automate lineage can help in this regard.
- Don’t let syntax issues hold up your migration. Instead, accept they are part of the process and identify trends to expedite resolution post migration.
- Monitor data quality to catch inevitable silent errors that will arise.
When you move to a new environment, there is always an inherent skepticism from users. This is a fragile moment in time as the new system will need to earn their trust before it’s adopted with wide open arms.
For example, one healthcare company we work with was ingesting hundreds of files from healthcare providers a day and their .net applications on their SQL server couldn’t handle the compute for critical tasks. They decided to launch a greenfield migration to Snowflake and have all ingestion points land in their new data warehouse first.
Because of the high-stakes nature of their data, they wanted to ensure it had best-in-class protection (thanks Snowflake row-level security!) as well as reliability. With Monte Carlo, they are confident healthcare providers and patients will be able to fully trust their data, which plays an important role in insurance reimbursements.
Following your migration to the Snowflake data cloud, some ongoing maintenance will be required to fully optimize your usage. We discussed some of the features Snowflake provides to help optimize costs including:
- Auto-suspend/resume
- Resource monitors
- Query tags
- Queries for determining the most expensive queries run in the last 30 days
- Table clustering, search optimization service, and materialized views
Data observability solutions like Monte Carlo parse SQL query logs and provide additional context on an organization’s data health to simplify Snowflake optimization. This includes:
- Volume alerts in near-real time
- Heavy and deteriorating queries reports (available with other data health insights in the Snowflake Data Marketplace!)
- Unused tables (with ownership so you can check with a human before you delete).
These features were helpful for Shoprunner to get visibility into how the data was used and determine which data pipelines could be turned off according to Valerie Rogoff, director of analytics data architecture.
That’s the beauty of Monte Carlo because it allows us to see who is using data and where it is being consumed. This has allowed us to actually free up some of our processing time from unused data elements which no one was using anymore and were no longer relevant.
Data trust and increasing Snowflake adoption
In our interview with Snowflake Director of Product Management Chris Child, he talked about a three step process for maximizing value. He said:
First, get all of your data in one place with the highest fidelity. Just get the raw data in there.
Second, come up with repeatable pipelines for getting data to your analysts. You don’t want to go back to the raw data every time you want to do something.
Third, is to get people across the organization to trust the data and make sure they are confident in the dashboards they are seeing. This last part is hard.
Indeed, earning data trust is absolutely critical to obtaining adoption. Vimeo, which stores more than a petabyte in Snowflake, started prioritizing building data trust and availability across the entire organization. Their former VP of engineering, Lior Solomon, said:
We’re actually expanding our machine learning teams and going more in that direction. It would be hard to advocate for hiring more and taking on more risk for the business without creating that sense of trust in data. We have spent a lot of the last year on creating data SLAs or SLOs making sure teams have a clear expectation of the business and what’s the time to respond to any data outage.
And it’s not just internal stakeholders who need to trust the data. More companies are leveraging Snowflake to build external data products. For these organizations, data observability is bordering on a requirement for these data products that will be customer facing.
For example, one media company is leveraging Monte Carlo to ensure the data powering their online streaming service recommendation engines is reliable. Another healthcare customer is building new customer facing data products where data quality and accuracy will be highly critical and could even be the make or break point for its ability to monetize successfully.
The bottom line is if your organization is going to push the envelope for what you can do with Snowflake, you need to know you have a Snowflake observability partner that has your back making sure no bad data creeps into your pipeline.
Snowflake observability is essential
As teams ingest and transform significant amounts of data within Snowflake, it’s crucial that data is trustworthy and reliable.
When data quality is neglected, data teams end up spending valuable time responding to broken dashboards and unreliable reports. Organizational trust in data plummets, and business leaders revert to relying on instincts and anecdotal evidence instead of data-driven decision-making.
So along with storage and transformation, organizations need to prioritize data reliability to get the most out of their Snowflake investment. The positive results will speak for themselves and build momentum and buy-in for your next big initiative on the modern data cloud.
Interested in how you can add data observability to your Snowflake data cloud? Interested in Snowflake observability? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.