 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data trust is on it's way!
Thank you for scheduling a meeting with Monte Carlo! In the meantime, read more on data observability below:
Trusted by























What is data observability?
Data breaks – call it a fact of life. Poor data quality erodes stakeholder trust, data team resources, and company revenue. So, what’s a data engineer to do?
Enter: data observability. Data observability is a company’s ability to fully understand the health of its data at each stage in the data life cycle. In today’s world, data observability is a must-have for companies serious about accelerating data adoption and realizing the potential of their data investments.
-
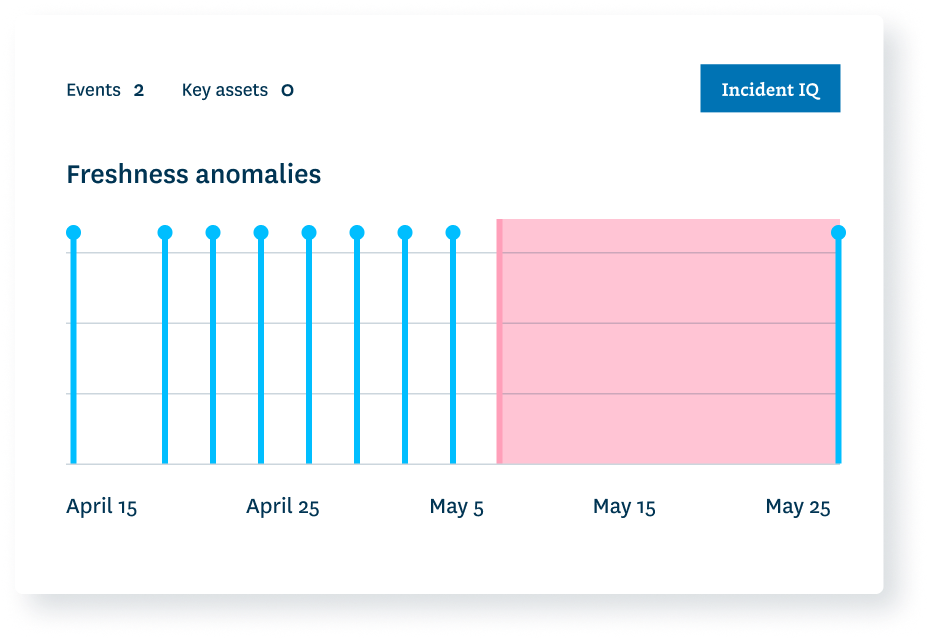
Freshness seeks to understand how up-to-date your data tables are, as well as the cadence at which your tables are updated. Freshness is particularly important when it comes to decision making; after all, stale data is basically synonymous with wasted time and money.
-
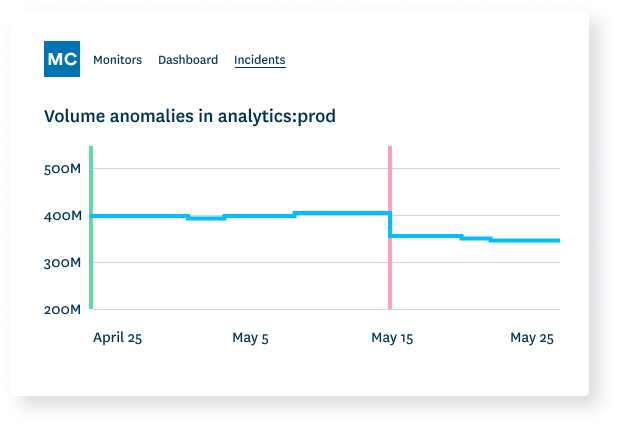
Monitoring data volume can help identify missing data, duplicate data and other issues. If 200 million rows suddenly turns into 5 million, you should know.
-
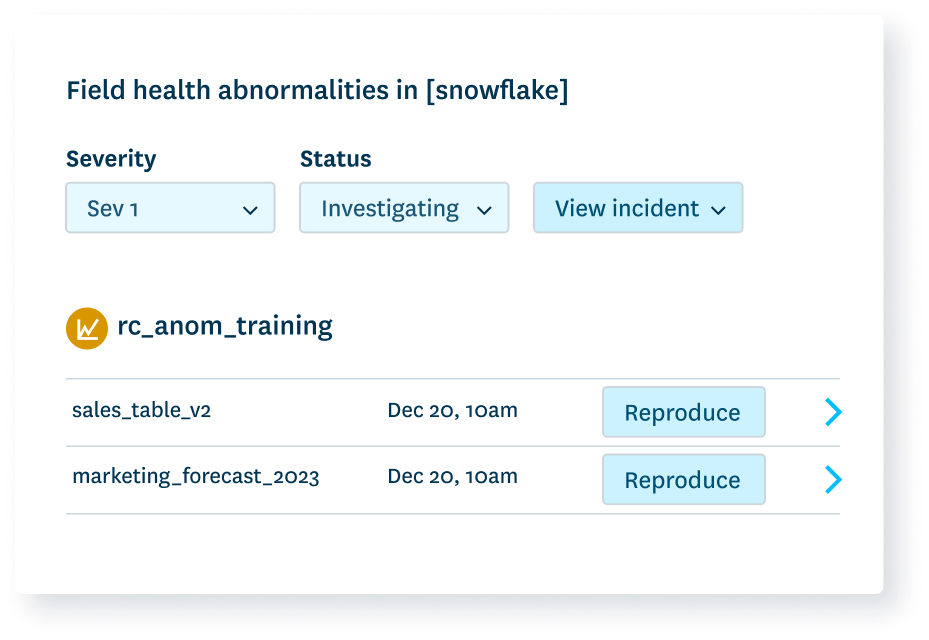
Is your data in an acceptable range? Quality gives you visibility into null values, duplicate data, and other specific issues based on what you should expect from your data.
-
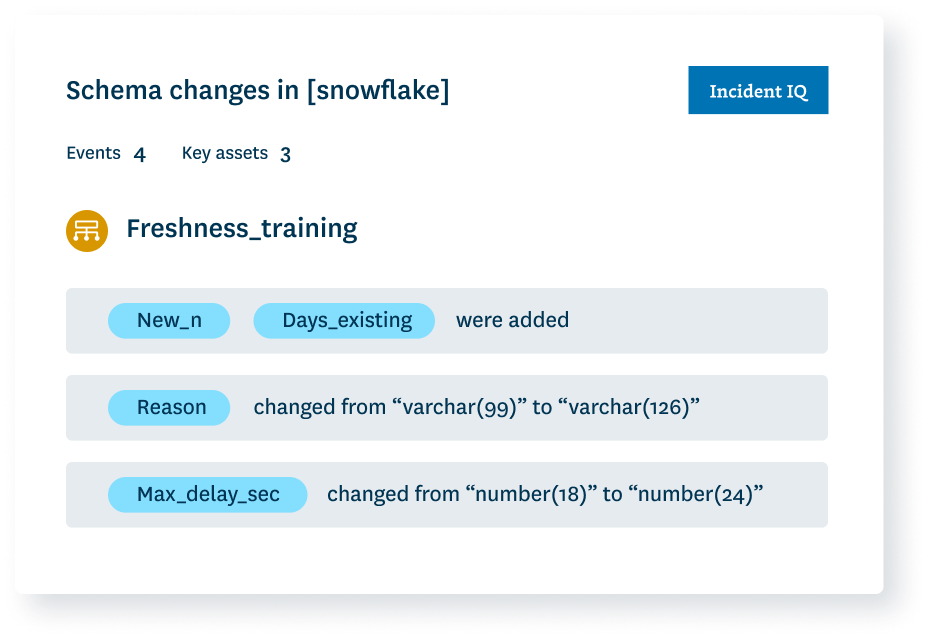
Were any changes made to the organization of your data? Monitoring who makes changes to these tables and when is foundational to understanding the health of your data ecosystem.
-
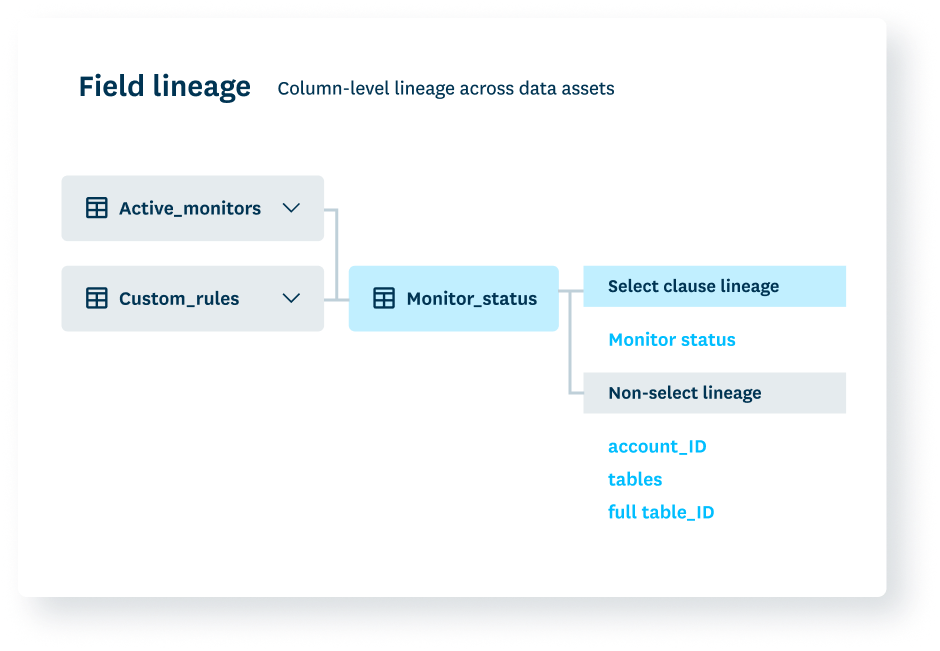
When data breaks, the first question is always “where?” Data lineage provides the answer by telling you which downstream assets were impacted, which upstream sources are contributing to the issue and which colleagues need to be looped in.

Out-of-the-box coverage across all your data tables, opt-in monitors for key assets, and monitors-as-code.

Don’t just sound the alarm when data incidents occur. Empower your data teams to resolve incidents in minutes.

Rich insights enable your team to proactively ensure data quality, and make better infrastructure investment decisions.