Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Observability for the Google Cloud Platform
Monte Carlo makes it easy for organizations on BigQuery to detect and resolve data quality incidents before they impact the business.


100% GCP coverage
Extend end-to-end data observability across 100% of BigQuery tables – and beyond.
Resolve incidents quickly
Equip your data team with the context they need to quickly resolve data anomalies and incidents in your BigQuery warehouse—before they impact the business.

Drive data adoption
By delivering data trust, Monte Carlo enables teams across your organization to develop more data, analytics, and AI use cases on BigQuery and the broader GCP portfolio.
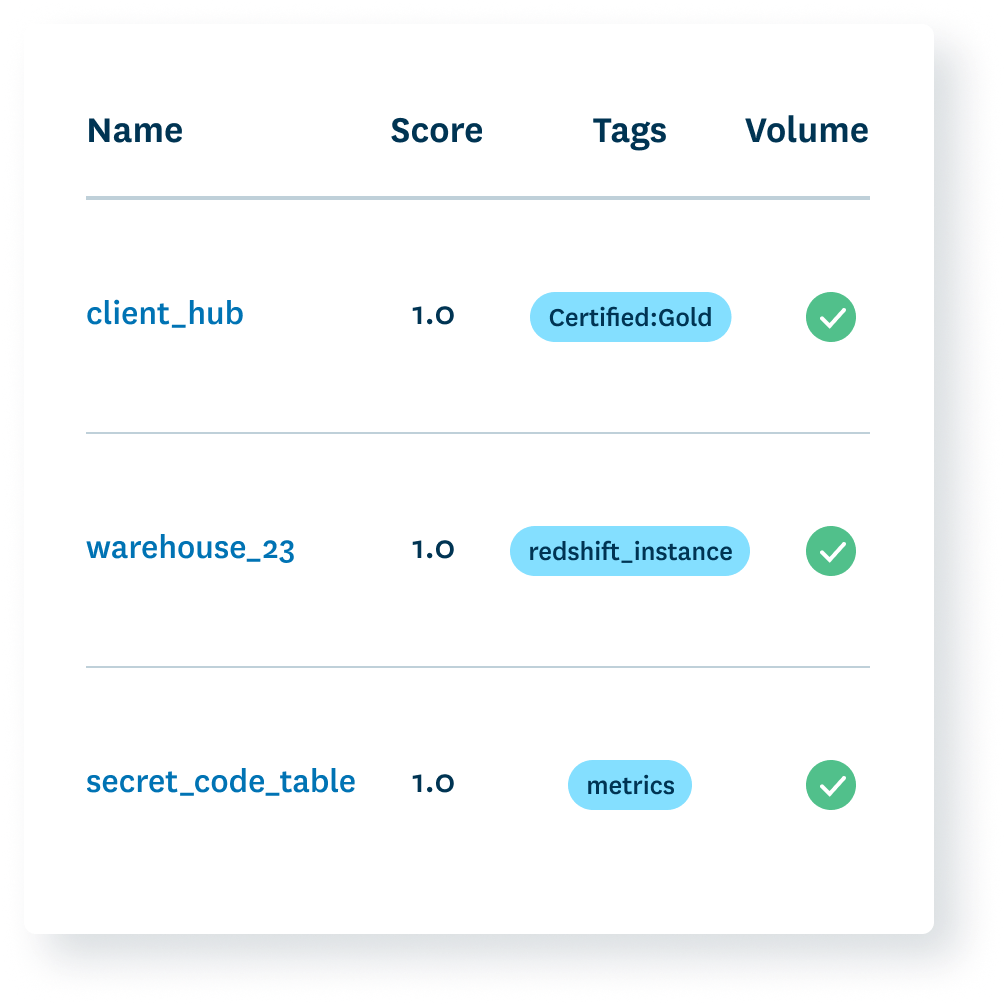
Automated data quality coverage across your warehouse
Don’t waste time writing tests when you have data observability. Monte Carlo deploys automated, end-to-end data freshness, volume, and schema checks out-of-the-box. Write custom checks for specific data quality use cases (distribution, field health, etc.) with our opt-in monitors.
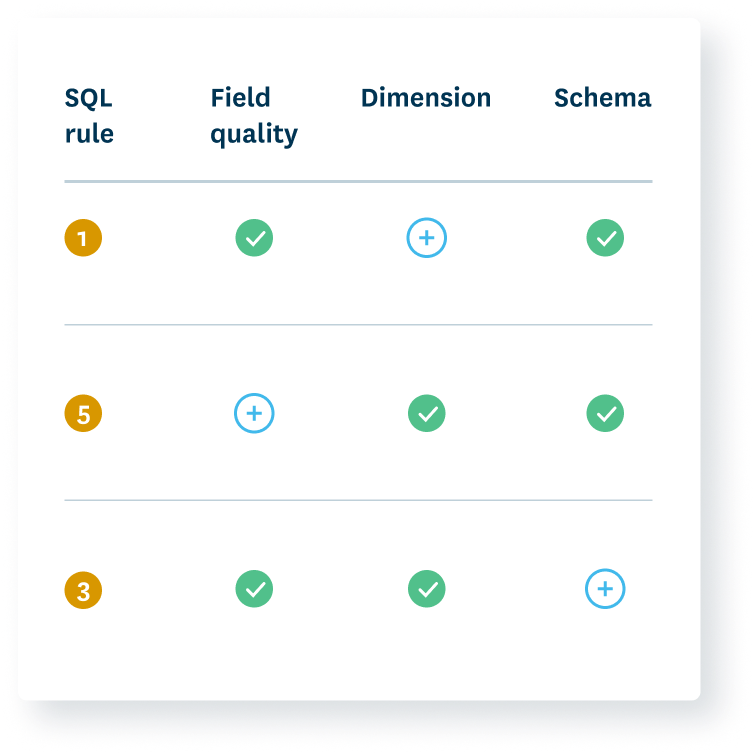
Extend lineage across your data stack
Monte Carlo automatically captures lineage from the point of ingestion to your BI tools, enabling your team to triage and prioritize data incidents before they impact your data consumers and stakeholders.
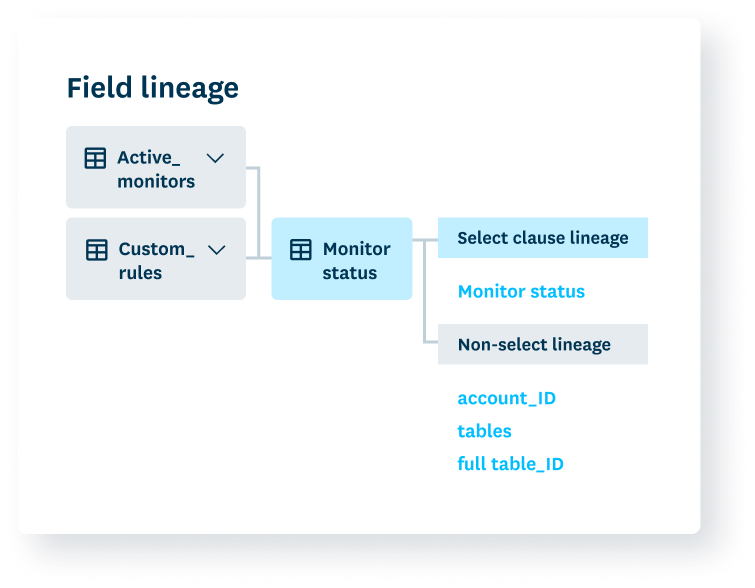
Automate root cause analysis
Monte Carlo equips teams with the context they need in a single interface and automatically identifies potential root cause to expedite incident resolution.