 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The New Rules of Data Quality


Francisco Alberini
Francisco is a product manager at Monte Carlo.

Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.
There are two types of data quality issues in this world: those you can predict (known unknowns) and those you can’t (unknown unknowns). Here’s how some of the best data teams are taking a more comprehensive approach to tackling both of them at scale.
For the past several years, data teams have leveraged the equivalent of unit testing to detect data quality issues. In 2021, as companies ingest more and more data and pipelines become increasingly complex, this single point-of-failure approach doesn’t cut it any more.
Don’t get us wrong: you SHOULD be testing your most important data. Data testing is a must-have to catch specific, known problems that surface in your data pipelines, and there are great tools to help you do it. That Segment app source and Salesforce data powered by Fivetran which flow into your Snowflake warehouse that are then transformed by dbt, and ultimately power the Looker dashboard your CEO uses for quarterly financial reports? Test away.
Still, even with automated testing, there’s extensive lift required to continue updating existing tests and thresholds, writing new ones, and deprecating old ones as your data ecosystem grows and data evolves. Over time, this process becomes tedious, time-consuming, and results in more technical debt that you’ll need to pay down later.
One customer at an e-commerce company — we’ll call her Rebecca — told us that her data engineering team used to rely exclusively on custom tests to catch data issues in their most critical pipelines… until they didn’t.
Rebecca and her team put their pipelines through the wringer with testing, but all it took was one unknown unknown (in this case, a distribution anomaly) to send the company into a tailspin. They lost revenue on transactions that couldn’t be processed, and her executives lost trust in the data.
Her team could track for known unknowns (i.e., we know this could be an issue, so let’s test for it), but they didn’t have a comprehensive approach to accounting for unknown unknowns.
The unknown unknowns in your data pipeline

Unknown unknowns refer to data downtime that even the most comprehensive testing can’t account for, issues that arise across your entire data pipeline, not just the sections covered by specific tests. Unknown unknowns might include:
- A distribution anomaly in a critical field that causes your Tableau dashboard to malfunction
- A JSON schema change made by another team that turns 6 columns into 600
- An unintended change to ETL (or reverse ETL, if you fancy) leading to tests not running and bad data missed
- Incomplete or stale data that goes unnoticed until several weeks later, affecting key marketing metrics
- A code change that causes an API to stop collecting data feeding an important new product
- Data drift over time can be challenging to catch, particularly if your tests only look at the data being written at the time of your ETL jobs, which don’t normally take into account data that is already in a given table
And that just scratches the surface. So, how can teams prevent these unknown unknowns from breaking their otherwise perfectly good pipelines? For most, it helps to separate these issues into two distinct categories.
The two types of data quality issues
If data testing can cover what you know might happen to our data, we need a way to monitor and alert for what we don’t know might happen to your data (our unknown unknowns).
- Data quality issues that can be easily predicted. For these known unknowns, automated data testing and manual threshold setting should cover your bases.
- Data quality issues that cannot be easily predicted. These are your unknown unknowns. And as data pipelines become increasingly complex, this number will only grow.
In the same way that application engineering teams don’t exclusively use unit and integration testing to catch buggy code, data engineering teams need to take a similar approach by making data observability a key component of their stack.
Introducing: a new approach to data quality
Just like software, data requires both testing and observability to ensure consistent reliability. In fact, modern data teams must think about data as a dynamic, ever-changing entity, and apply not just on rigorous testing, but also continual observability. Given the millions of ways that data can break (or, the unknown unknowns), we can use the same DevOps principles to cover these edge cases.
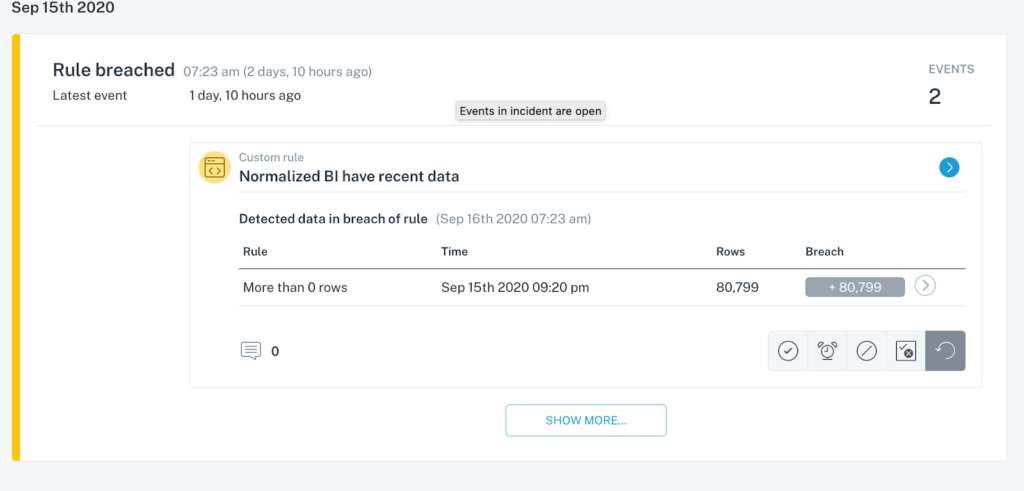
For most, a robust and holistic approach to data observability incorporates:
- Metadata aggregation & cataloging. If you don’t know what data you have, you certainly won’t know whether or not it’s useful. Data catalogs are often incorporated into the best data observability platforms, offering a centralized, pane-of-glass perspective into your data ecosystem that exposes rich lineage, schema, historical changes, freshness, volume, users, queries, and more within a single view.
- Automatic monitoring & alerting for data issues. A great data observability approach will ensure you’re the first to know and solve data issues, allowing you to address the effects of data downtime right when they happen, as opposed to several months down the road. On top of that, such a solution requires minimal configuration and practically no threshold-setting.
- Lineage to track upstream and downstream dependencies. Robust, end-to-end lineage empowers data teams to track the flow of their data from A (ingestion) to Z (analytics), incorporating transformations, modeling, and other steps in the process.
- Both custom & automatically generated rules. Most data teams need an approach that leverages the best of both worlds: using machine learning to identify abnormalities in your data based on historical behavior, as well as the ability to set rules unique to the specs of your data. Unlike ad hoc queries coded into modeling workflows or SQL wrappers, such monitoring doesn’t stop at “field T in table R has values lower than S today.”
- Collaboration between data analysts, data engineers, and data scientists. Data teams should be able to easily and quickly collaborate to resolve issues, set new rules, and better understand the health of their data.
Every data team is different, but we’ve found that this approach to testing and observability handles both your most likely data issues and the millions of other causes for broken data pipelines.
At the end of the day, the more known unknowns and unknown unknowns we can catch, the better.
We’d love to hear if this approach resonates with you! Reach out to Francisco Alberini, Scott O’Leary, and the rest of the Monte Carlo team.
Read more posts.





