Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monitors as Code: A New Way to Deploy Custom Data Quality Monitors From Your CI/CD Workflow

Francisco Alberini
Francisco is a product manager at Monte Carlo.
Monte Carlo releases Monitors as Code, a new feature that allows data engineers to easily configure new data quality monitors as part of their daily workflow.
As data teams scale, the operational overhead of deploying tests to cover all scenarios becomes increasingly difficult. And as data ecosystems grow, the sheer magnitude of unknown unknowns (in other words, data issues that you can’t predict) has grown, causing analyst bottlenecks, time-intensive fire drills, and loss of data trust.
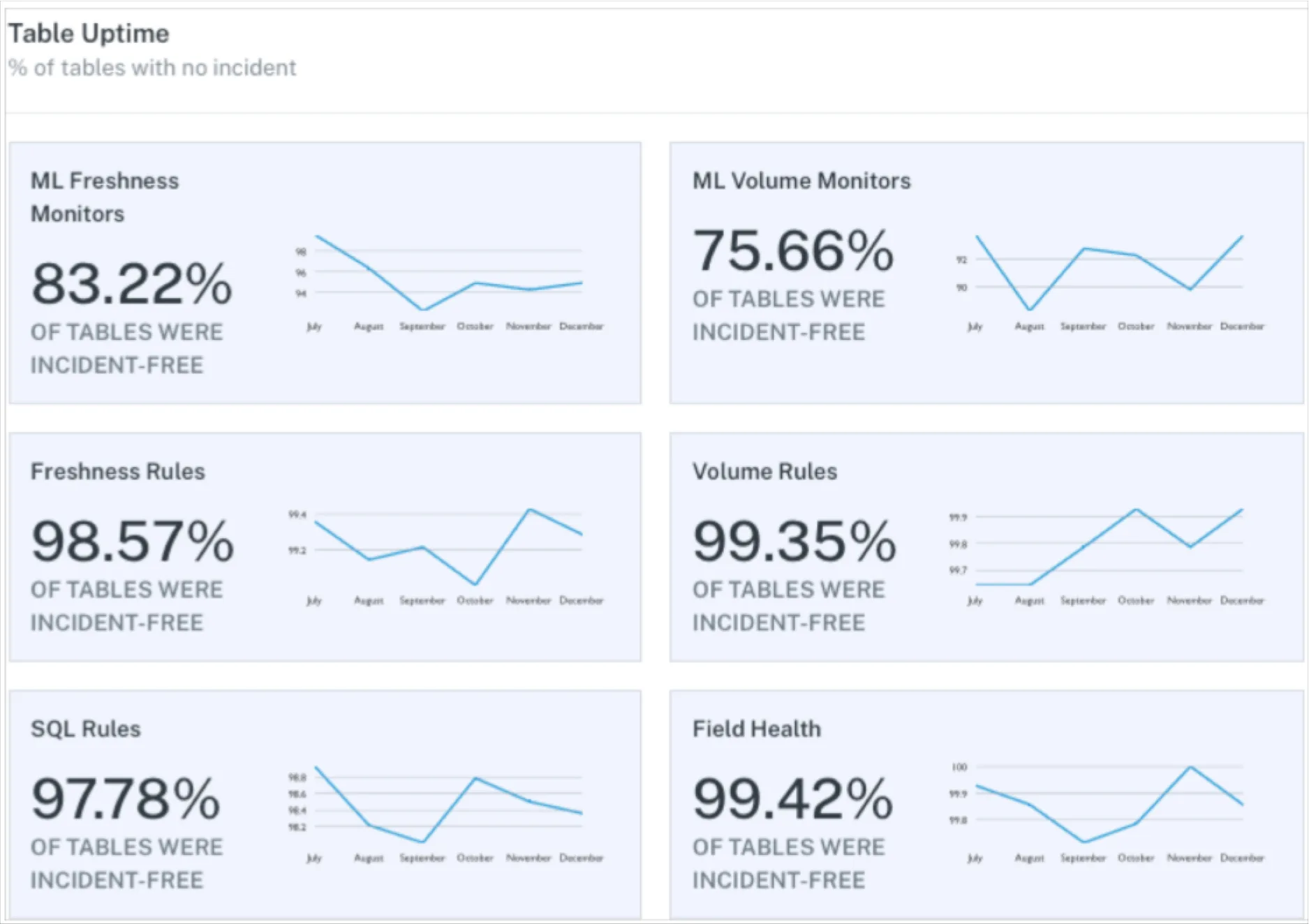
With Monte Carlo, data teams can deploy automatic monitors across every table in their data warehouse or data lake, and then monitor those tables for unexpected spikes or drops in freshness, volume, and unexpected changes to schema.
To supplement these automated monitors, Monte Carlo offers multiple custom monitors to identify and alert for specific anomalies within your underlying data – checking for anomalies such as null percentage, unique percentage within field values, and changes to the distribution of values. We also offer more in-depth customized monitors in the form of SQL commands that check for any condition that can be expressed in SQL. To date, Monte Carlo customers were able to deploy custom monitors via the Monte Carlo UI or through Monte Carlo APIs.
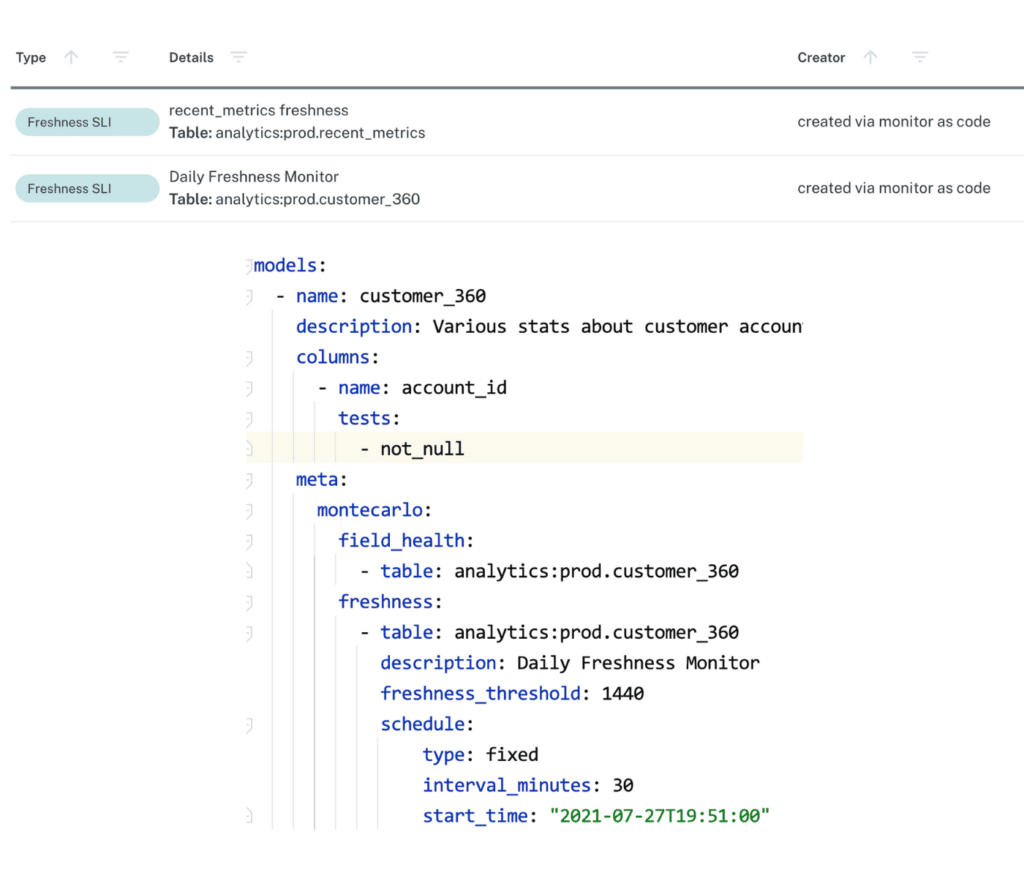
Today, we’re thrilled to announce we have released a code-based solution that allows customers to rapidly scale how they would deploy and manage Monte Carlo custom monitors, all from the comfort of their IDE – in other words, monitors as code. With monitors as code, data engineers can now configure monitors via a YAML config file and apply those monitors easily as part of the build process or within their CI/CD process.
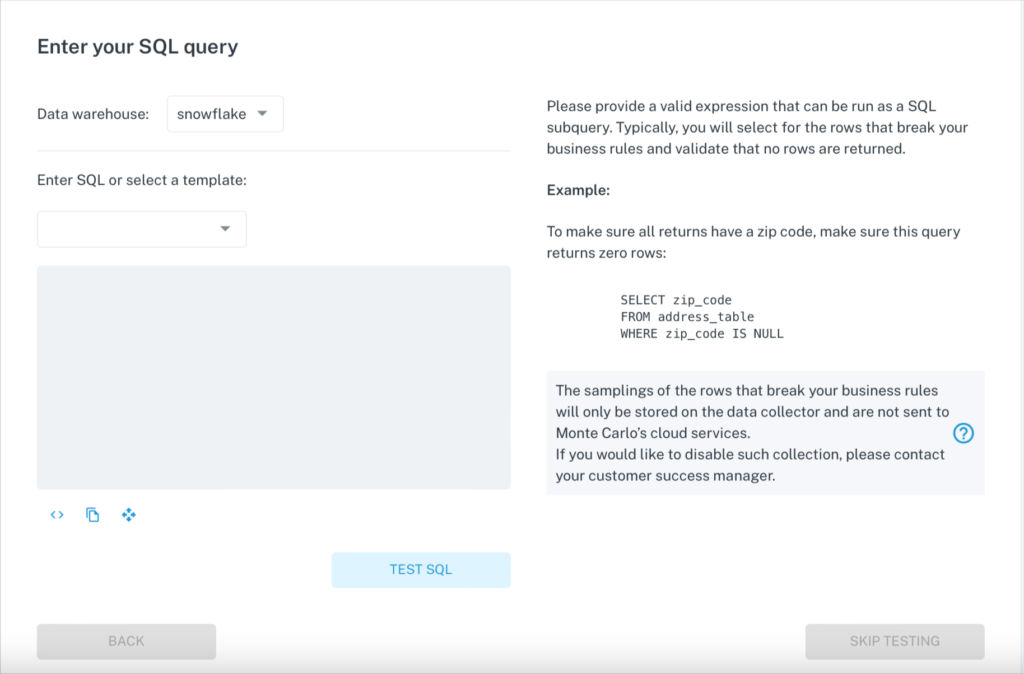
Why we’re excited about monitors as code – and you should be, too:
- It’s maintained in source control so changes are properly tracked and approved.
- It can be automated (e.g. you can easily create 100 monitors without repetitive UI clicking, you can enforce certain standards, etc.)
- It naturally fits into the data engineering workflow (which consists of writing code, tests, and now, monitors.)
- It makes creating new monitors consistent and predictable, and less error-prone (e.g. you won’t get someone accidentally deleting/updating monitors.)
For more information on how to implement monitors as code in your CI/CD process, check out our documentation.
What our customers have to say
Monitors as Code has made it easier for data teams to set and refine data quality monitors as part of their daily workflow, helping them achieve end-to-end data trust across critical data sets.
“Wow – this is very cool! I tried to set this up by doing it via the graphQL API and gave up. I can’t wait to share this with the analysts,” – Data Engineer at a 500-person AdTech company.
Interested in learning more about Monitors as Code and Monte Carlo’s end-to-end Data Observability Platform? Reach out to Francisco and the rest of the Monte Carlo team for a demo.
Our promise: we will show you the product.
Read more posts.