Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Good Tales of Bad Data

Martín Alonso
Martín is an engineering lead at Monte Carlo.
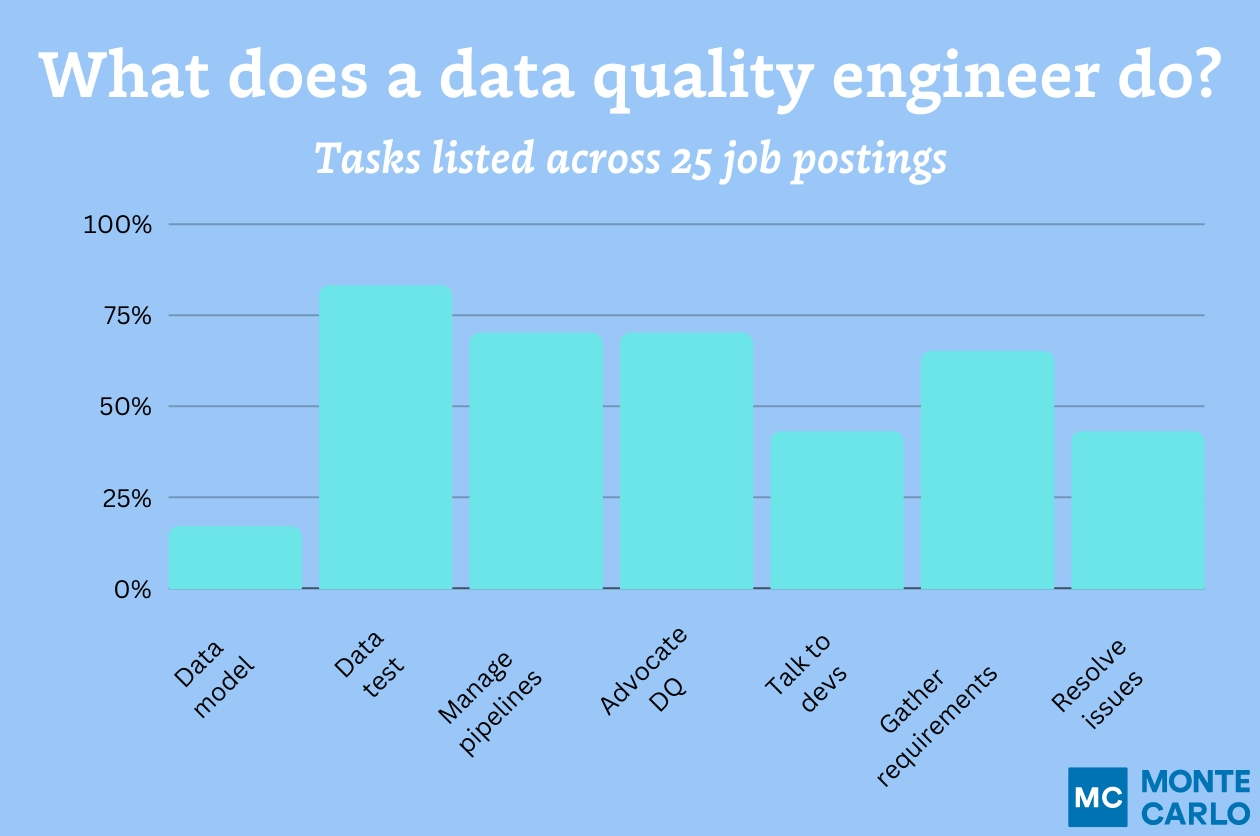
Meet Julia. She’s a data engineer. Julia is responsible for ensuring that your data warehouses and lakes don’t turn into data swamps, and that, generally speaking, your data pipelines are free of bad data and in good working order.

Julia is happy when nothing breaks, but like any good engineer, she knows that this is near-to impossible. So, she just wants to be the first to know when issues do arise so that she can solve them.
Meet Ted. He’s a data analyst. Ted is known by his company as the “SQL King” because he’s the go-to query wrangler for their Marketing, Customer Support, and Operations teams. He’s an expert in Tableau, and knows all the Excel hacks. Ted is also happy when nothing breaks, and like Julia, knows that this is impossible. However, Ted doesn’t want bad data to ruin his analytics, making his life and the lives of his stakeholders miserable (more on that later).

Meet Alex. Alex is a data consumer. She might be a data scientist, a product manager, a VP of Marketing, or even your CEO. Alex uses data to make smarter decisions, whether that’s what the title of her new product should be or which pair of lucky socks she should wear to tomorrow’s board meeting.
Alex, or anyone else at the company for that matter, can’t do their job if they can’t trust their data. We call this phenomena data downtime. Data downtime refers to periods of time where your data is inaccurate, missing, or otherwise erroneous, and spares no one, sort of like death and taxes. Unlike death and taxes, however, data downtime can be easily avoided if acted on immediately.
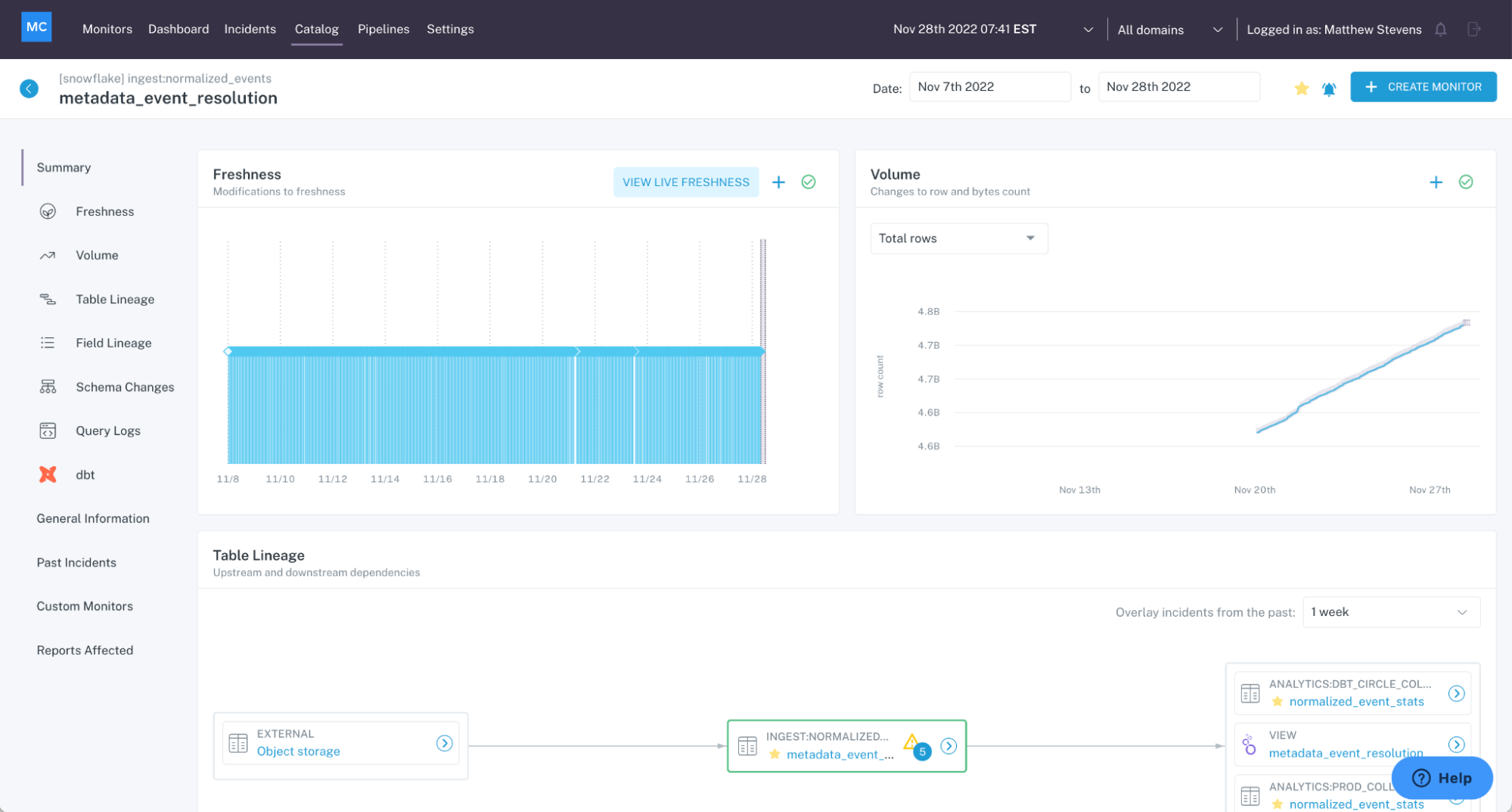
When raw data is consumed by your data pipeline, it’s abstract and meaningless on its own. It doesn’t really matter if there’s data downtime because no one is using it quite yet – other than Julia, to pass it on. The problem is, she doesn’t always know if data is broken.
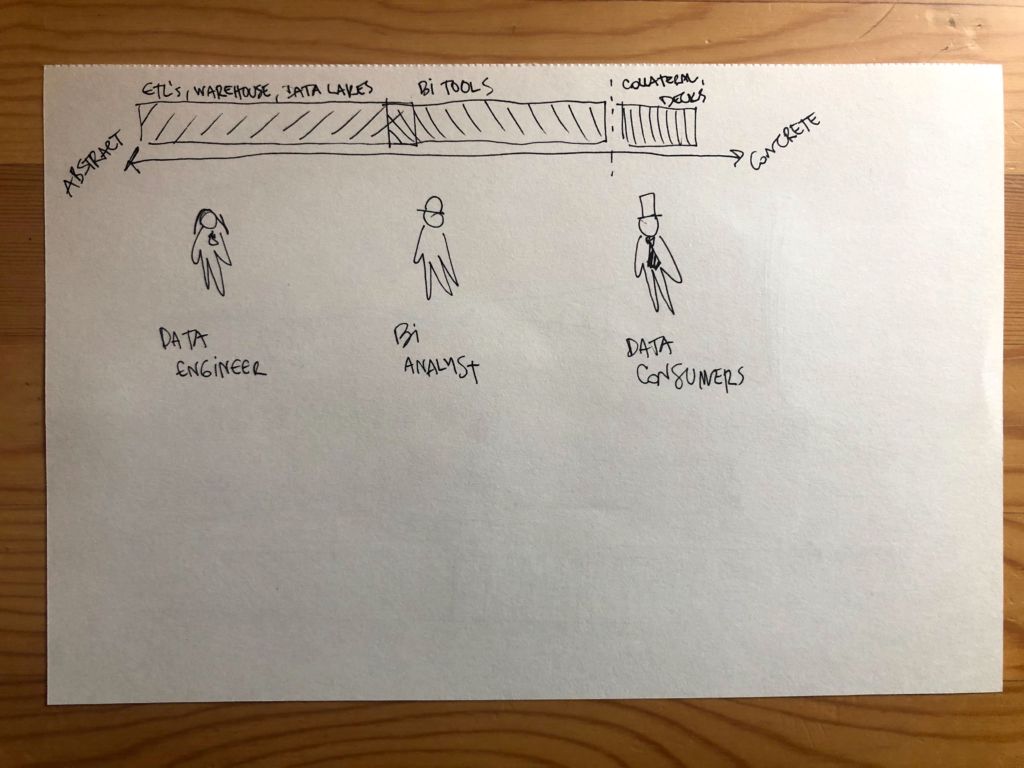
As data moves through the pipeline, it becomes more concrete. Once it reaches the company’s business intelligence tools, Ted can start using it, transforming what was formerly vague and abstract into Excel spreadsheets, Tableau dashboards, and other beautiful vessels of knowledge.
Ted can then transform this data (now nearing full maturity) into actionable insights for the rest of his company. Now, Alex can create marketing collateral and PDFs and customer decks with this data, which is polished and concrete and bound to save the world. Or is it?
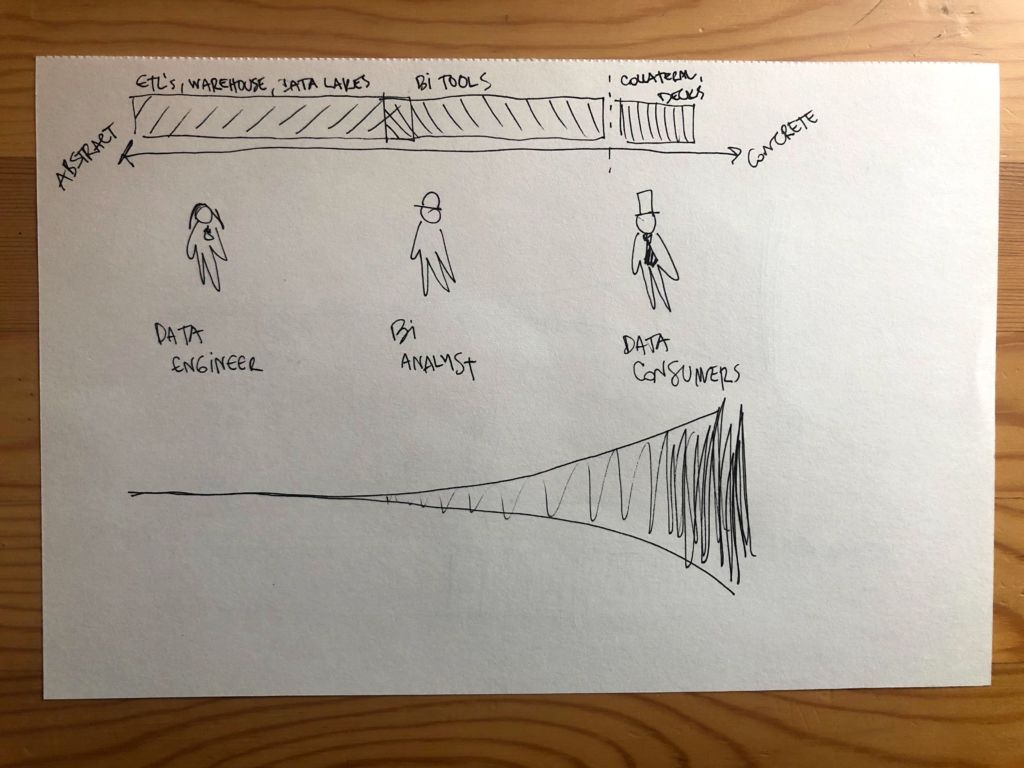
As data errors move down the pipeline, the severity of data downtime increases. There are more and more Teds and Alexs using the data, many of whom have no idea if what they’re looking at is right, wrong, or somewhere in between until it’s too late.
When is too late, you might ask?
Too late is when Julia is paged at 3 a.m. Monday morning by Ted who was called by Alex, his skip-level manager and the VP of Sales, only a few minutes before about a wonky report he was supposed to present the next morning to their CEO. Too late is when you’ve wasted time, lost revenue, and eroded Alex — and everyone else’s — precious trust.
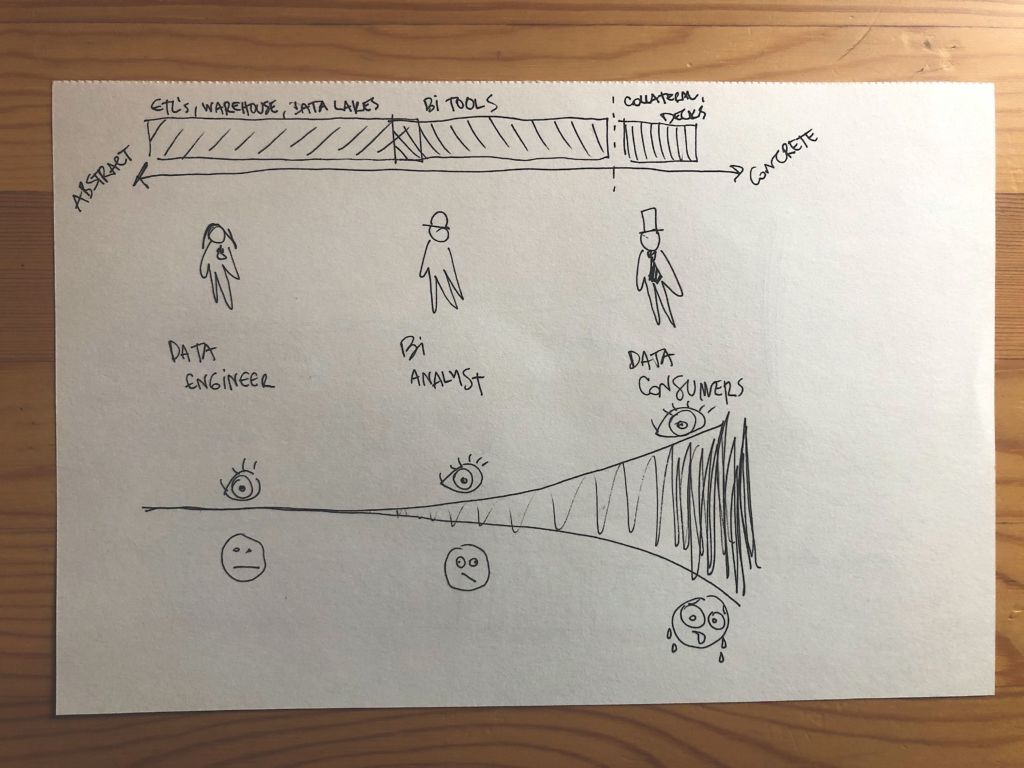
The more concrete and further removed the data gets from Julia’s raw tables, the more severe the impact. We refer to this as the cone of data anxiety.
Disaster struck and Julia had no idea why, let alone that it had happened. If only she had caught the data downtime immediately — right when it hit — instead of through Alex and her other data consumers, disaster could have been avoided.
Worst of all, she was in the middle of a once-in-a-lifetime dream. Cotton candy clouds, chocolate fountain waterfalls, and no null values. The complete opposite of the reality she was facing at 3 a.m. on Monday morning.
Sounds familiar? Yeah, I’m with you.
If data downtime is something you’ve experienced, we’d love to hear from you! Reach out to Barr Moses with your own good tales of bad data or book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.