Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Every Company is a Data Company (But Not Every Company is Good at Data)


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
A few years ago, it quickly became a cliche to say that every company was a tech company. Sure, every company is — in a way. But another trend has followed on the heels of that one, and this one is even more broadly applicable: every company is a data company nowadays. Heck, every organization is becoming a data organization!
The benefits to becoming data driven are clear; obviously, if you can make decisions based on data, and measure the impact of those decisions, it’s a much more effective and efficient approach than the guesswork or gut-feeling that used to drive so much of business. So it’s no surprise that there is a strong trend in the market to become data driven, in part because cloud technologies and the growing usage of SaaS make data more accessible than ever.
But not so fast. I’m also seeing that while there’s more appetite than ever to be data-driven, it’s harder than ever to be good at it. In fact, I’d say there’s actually an opposite trend around the fundamentals of data (accuracy, quality, reliability, governance, access, protection, security) — these are all extremely challenging to get right, and getting worse to manage.
But here’s the kicker: Not only do these trends exist simultaneously, they actually reenforce each other. Meaning, the more you try to become data-driven (trend up), the harder it is to get the fundamentals right (trend down). And the less reliable the data is, the less seriously organizations take their data efforts… and the negative cycle continues.
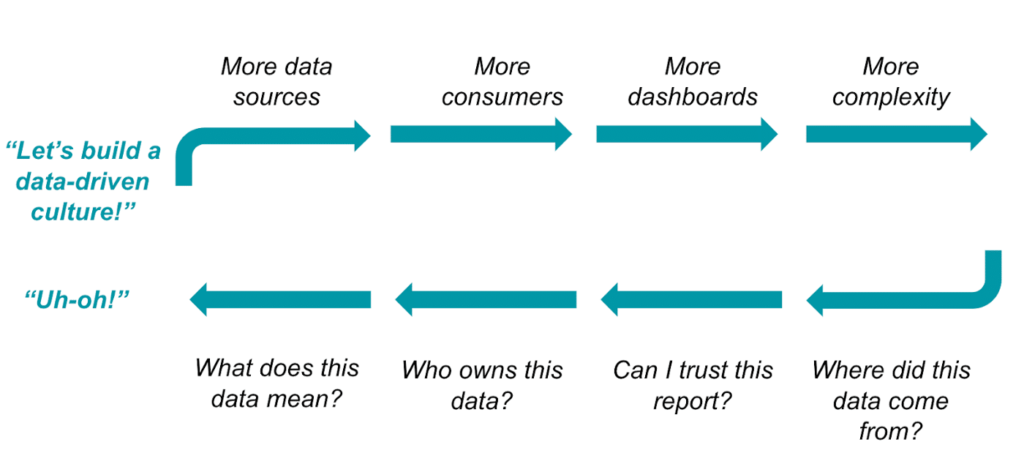
What can we do about this? To start, I think it’s helpful to think about how we got here. There are a number of reasons for this inverse relationship between data appetite and data success. For one, data has been layered on as the superficial icing on the cake — not the cake itself — with a focus on artificial intelligence, dashboards and the UI side of data instead of reimagining the structure to begin with. In addition, and perhaps relatedly, data tends to be a fragmented objective across the organization.
It’ll take changing both those realities to ensure that we aren’t cannibalizing our own efforts by working with unreliable data. In many ways, it amounts to getting back to basics with a mindset shift:
- It’s better to have no data than to have unreliable data
- To trust data, we must know where it came from, what it means and what assumptions it is based on
- We must manage the reliability of data all the way from the source to the dashboard, report or machine learning model we consume
Why is it that our standard for reliability is so high for everything we do in business — it’s part of what encourages this data driven trend in the first place! — but somehow we’ve come to accept the fact that our data is unreliable? I continue to be perplexed by this every day. If you’re feeling the same — what have you seen that helps organizations turn the tide on this paradox?
Talk to us by booking an open time with the form below.
Our promise: we will show you the product.
Read more posts.