Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Demystifying Data Observability


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
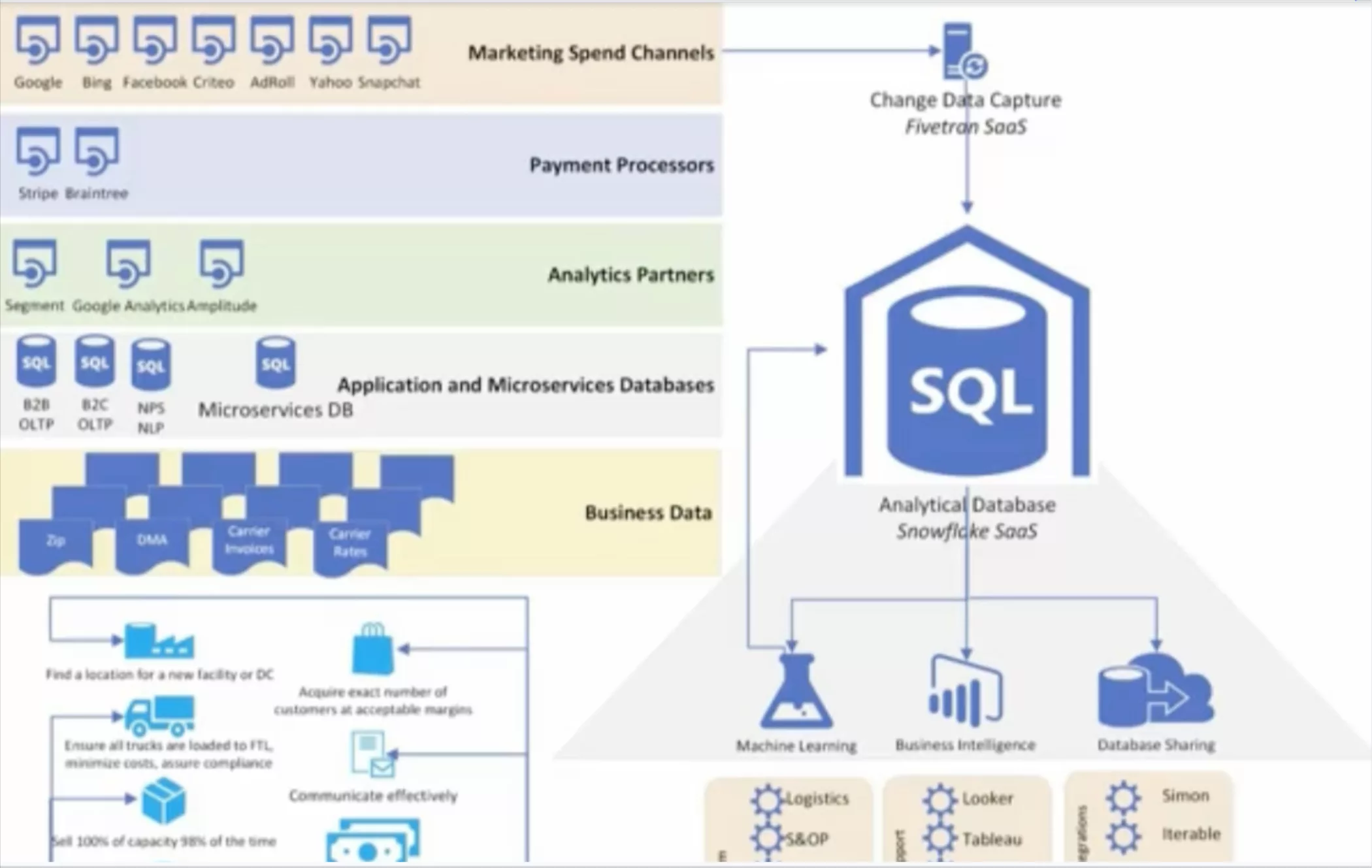
As companies ingest more and more data and data pipelines become increasingly complex, the opportunity for error grows, manifesting in everything from a broken dashboard to a null value.
On Thursday, November 12 at 12 p.m. EST/9 a.m. PST, we’ll be discussing how to solve this problem during a data observability webinar with the Data Engineering and Business Intelligence Leads at Yotpo, an e-commerce marketing platform.
In advance of our conversation, here are 3 tell-tale signs your data engineering team could benefit from data observability, the modern data stack’s newest layer.
A customer recently asked me: “how do I know if I can trust my data?”
When I was the VP of Customer Success at Gainsight, this question came up a lot. Every data organization I worked with was different, with their own service level agreements (SLAs), security requirements, and KPIs for what “accurate, high quality data” looked like. Between all of these data teams, however, a common theme emerged: the need for a better approach to monitoring the reliability of data and eliminating data downtime.
Data downtime refers to periods of time when data is missing, inaccurate, or otherwise erroneous, and it can range from a few missing values in a data table to a misstep in the data transformation process. As companies increasingly leverage more and more data sources and build increasingly complex data pipelines, the likelihood of data downtime striking only grows.
I remember thinking to myself: Wouldn’t it be great if there was a way for data teams to monitor and alert for these incongruities the same way that software engineers can track application downtime through observability solutions like New Relic and Data Dog?
Five years ago, there wasn’t a vocabulary — or an approach — holistic enough to address this evolving need. In 2020, we’re finally there: world, meet data observability.
In previous articles, I’ve discussed why data observability is foundational to trusting your data (in other words, data reliability), but what does that look like underneath the hood?
Here are 3 tell-tale signs your data team should invest in data observability:
1. Someone changes a field upstream, resulting in missing or partial data downstream
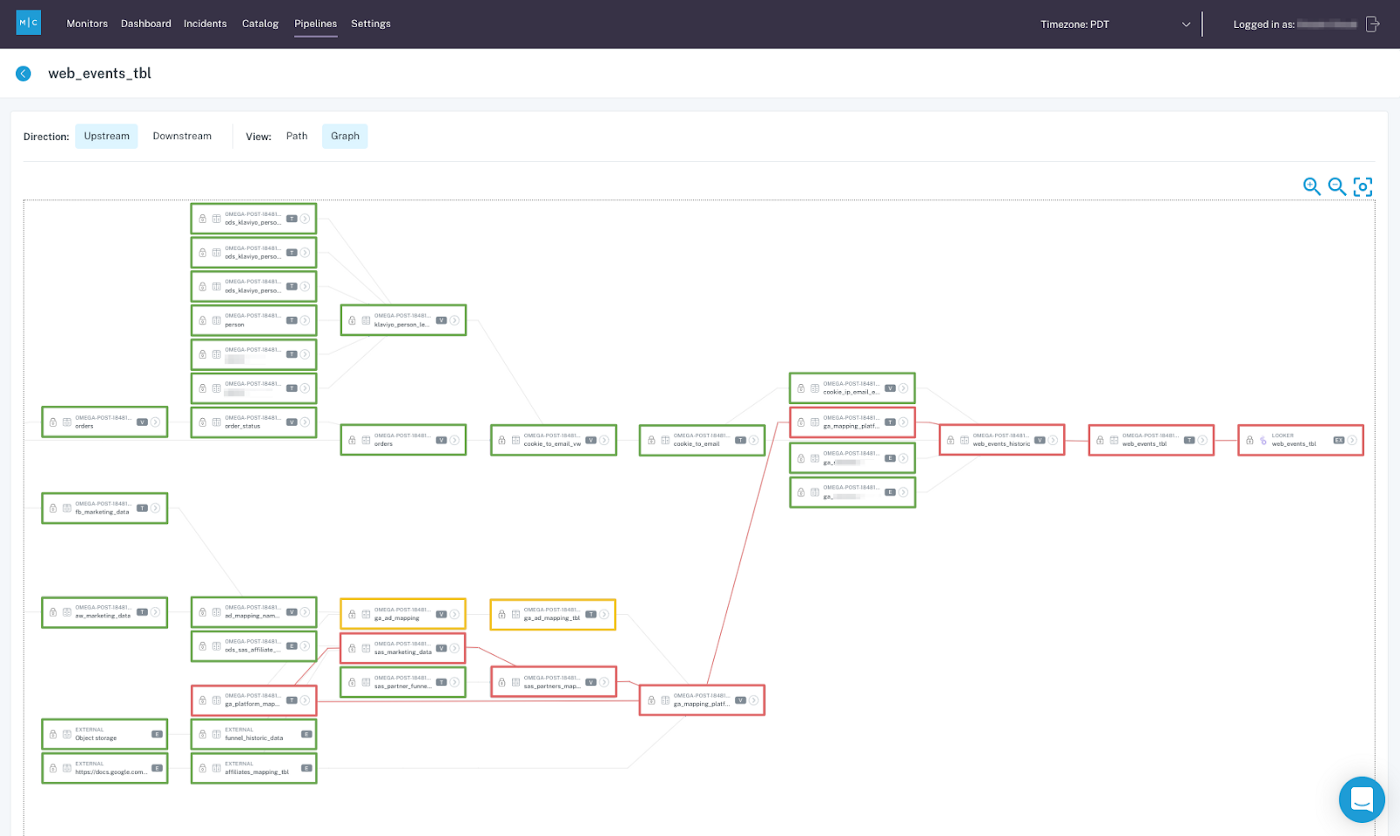
Situation
Meet Stephanie. She’s a data scientist. Stephanie is responsible for modeling a data set about the success of her company’s demand-gen marketing campaigns. One day, Ken, a member of the advertising team, changes a field in that data set, causing her latest A/B test to generate wonky results. Unfortunately, Stephanie has no way of knowing why her results were off, and instead of proudly presenting the results of her experiment at her company’s next Data Science All-Hands, she scraps the experiment and starts from scratch.
Solution
Data observability fixes this lack of end-to-end visibility into your data pipeline’s upstream and downstream dependencies so you can identify where data fire drills occurred and resolve them quickly. Even when pipelines break and A/B tests go awry, you can identify the root cause of the error and update your experiment accordingly, increasing trust in your data and reducing compute costs.
#2: Your Looker dashboard hasn’t been updated in 24 hours
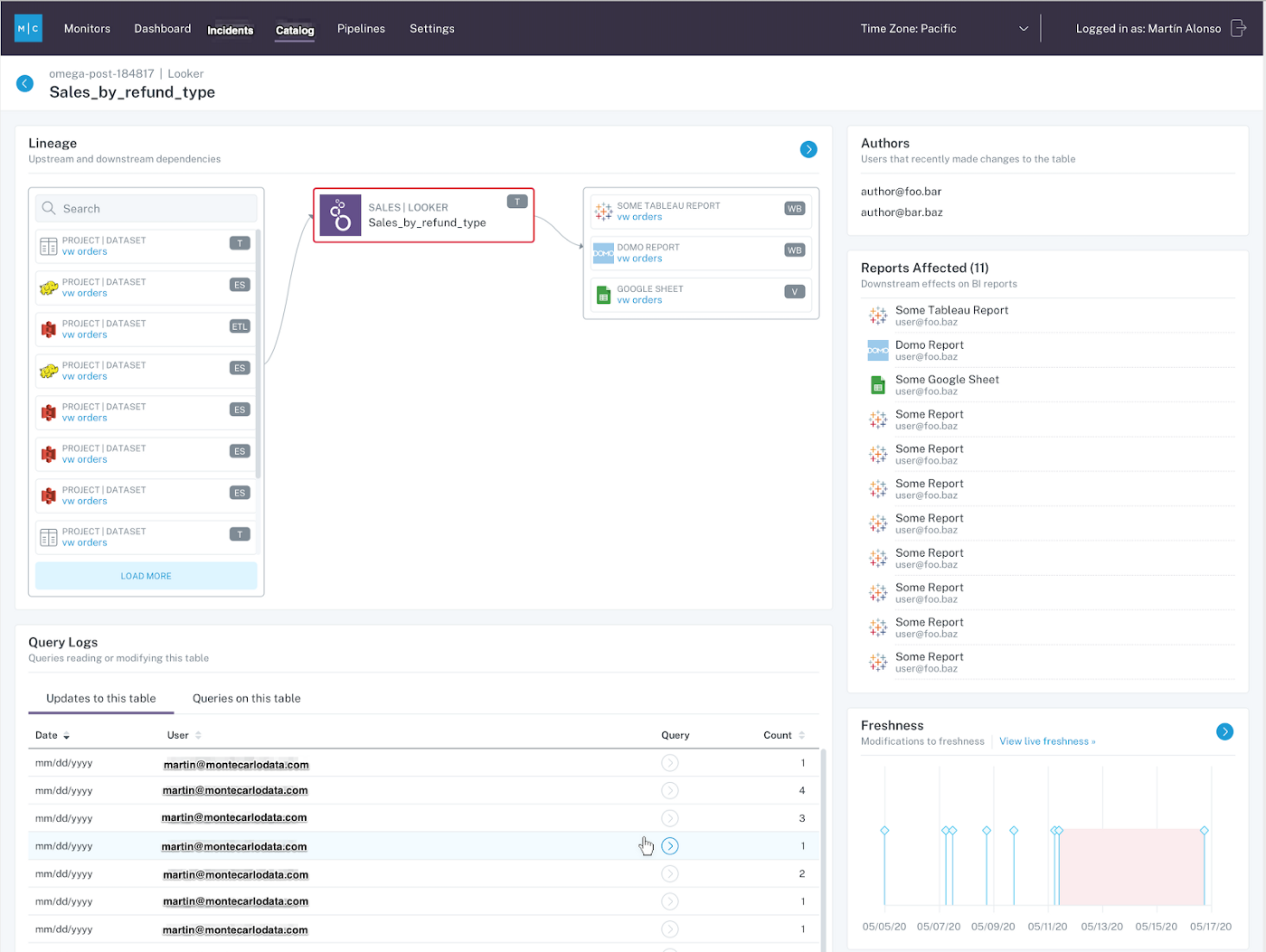
Situation
At Stephanie’s company, the Marketing Analytics team uses Looker to visualize how many sales qualified leads are generated per day as a result of a new billboard in NYC’s Times Square. Minutes before a Q4 planning meeting between their CEO, the VP of Marketing pings Stephanie on Slack: “The data is all wrong… what happened?!”
She opens Looker and realizes the numbers, which are normally updated every 15 minutes, haven’t been touched in 24 hours!
Solution
A good approach to data observability provides ML-based detection of freshness issues and monitors your data for abnormalities, alerting you in real-time. A great data observability strategy will do all of that, AND provide a single, pane-of-glass view into your data health, cataloging your metadata across your various data sources. Moreover, automated detection reduces manual toil and frees up time to work on projects that will actually move the needle for your company.
#3: Miscommunication between data analysts, data scientists, and data engineers lead to data fire-drills
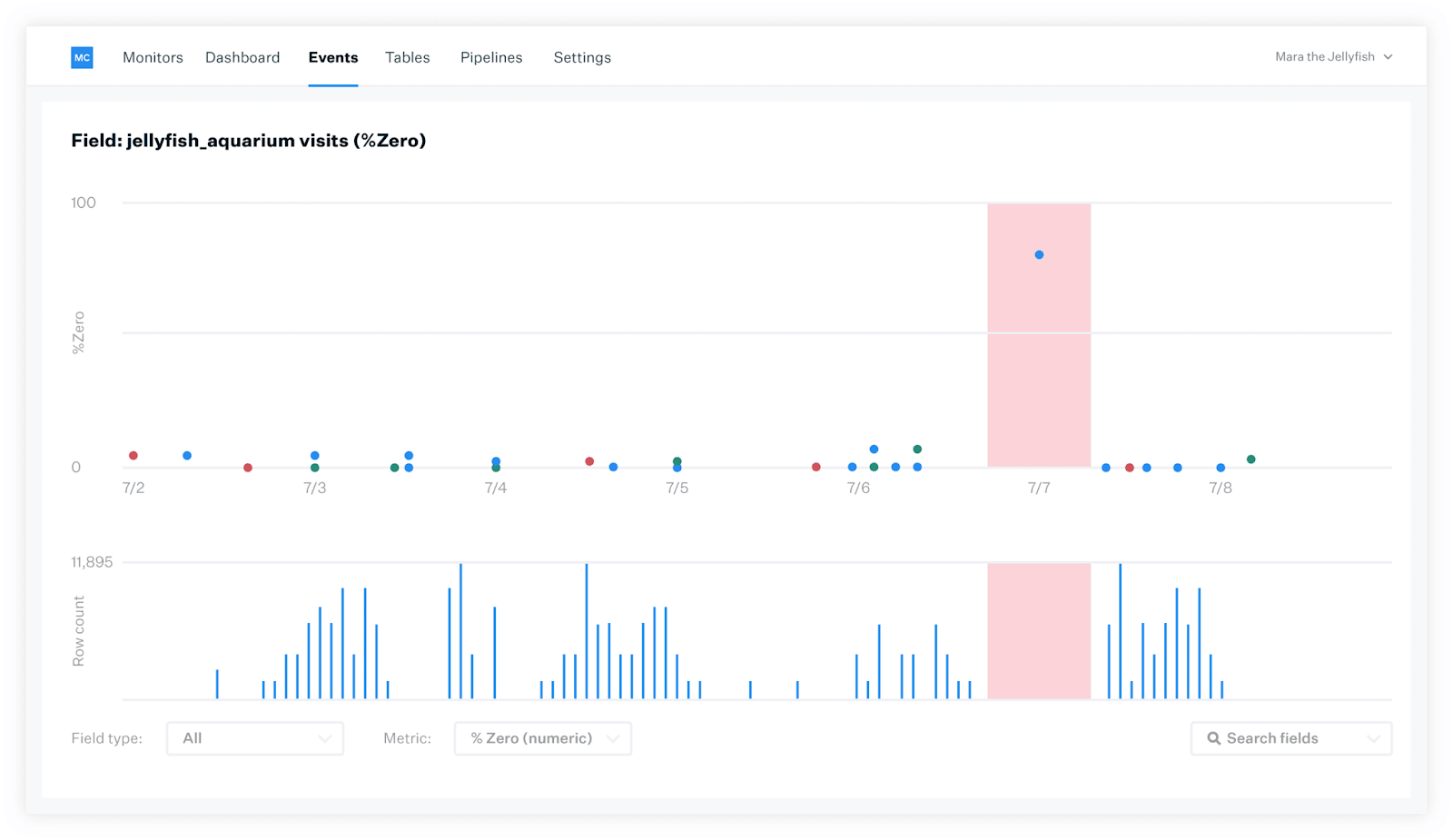
Situation
Stephanie’s team is building a new data model to better understand what type of prospective customer is most interested in her company’s product, filtered by geographic region and industry sector. This is a cross-team collaboration between data analysts, data scientists, and data engineers, and there’s a lot riding on the results.
When Stephanie deploys the model, nothing happens. She tries again. And again. Still, no dice. Unbeknownst to her, a data scientist in Chicago has made a schema change to a data set that’s forever altered the model as she knows it. There’s no way to tell what data was updated and where the break happened, let alone how to fix it!
Solution
A strong approach to data observability will enable teams to collaboratively triage and troubleshoot data downtime incidents, allowing you to identify the root cause of the issue and fix it fast. Perhaps most importantly, such a solution prevents data downtime incidents from happening in the first place by exposing rich information about your data assets so that changes and modifications can be made responsibly and proactively.
While data downtime varies from company to company (and team-to-team), data observability can help. Maybe you even saw yourself in Stephanie and have some of your own good tales of bad data to share, too!
I’m all ears.
Interested in learning more? Reach out to Barr Moses and the rest of the Monte Carlo team!
Our promise: we will show you the product.
Read more posts.