Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Closing the Data Downtime Gap


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
“Our data is 100% reliable” — said no one ever.
In a previous blog post, I wrote about “data downtime” and its meaning for data-driven companies. As data becomes more mission-critical to organizations and more complex for data teams to manage, we’ll see the rise of data downtime in importance and urgency. Companies have various approaches to managing data downtime; those who have mastered it start by realizing it requires proactive, systemic attention.
Companies that are able to manage data downtime achieve great benefits.
Here are a few:
- Data teams significantly reduce the amount of time spent on fire drills, escalations and troubleshooting data issues. Instead, they can focus on building great infrastructure and deriving value out of data.
- Data teams move faster on changing, adding, or upgrading their data infrastructure, since they can reliably know things are not going to break along the way.
- Data teams gain the trust and respect of business executives, product managers and other stakeholders since they present consistently trustworthy data.
Much has been written about solutions, some great examples include these from Intuit and Netflix — yet I’ve found there still isn’t a standard industry best practice. Curious as to why, I interviewed and collected information from over 80 organizations about their approach to data downtime. Here are some of my observations:
Data downtime happens to almost everyone on their quest to become data-driven. There are various degrees of severity, but it’s not unique or isolated to a specific industry, skill set, technology or organizational structure. So in case you’re wondering — no, you’re not alone. 🙂
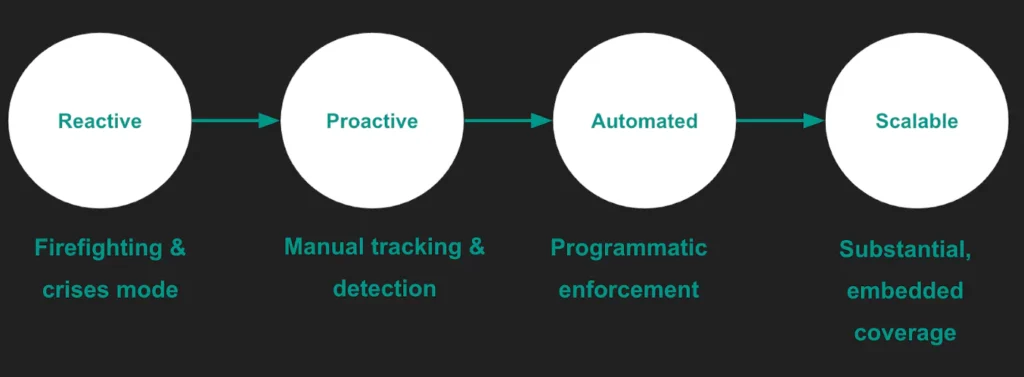
Organizations follow a journey on their path to realizing maximal data uptime — I call it the data reliability maturity curve. The journey typically starts when the company begins to experience hyper-growth, starts using data in a new and intense way, and/or as a result of an important business metric or customer which has been impacted due to bad data.
The data reliability maturity curve
There are four main steps in the data reliability journey:
#1 Reactive: data teams start their morning with the daily fire-drill, and spend the first half of their day triaging a data problem. They spend significant amounts of time in crisis mode and are slow to make progress on important initiatives. As a result, the organization struggles to use data effectively in the product, machine learning algorithms, or business decision making.
#2 Proactive: the data team develops manual sanity checks and custom QA queries to validate their work, perhaps also receive Slack or email alerts when things go wrong. This requires discipline and active collaboration between engineering, data engineering, data analysts, and data scientists. Examples:
- Validating row counts in critical stages of the pipelines
- Tracking time stamps to ensure freshness of the data
#3 Automated: having reliable, accurate data becomes a priority. Validation queries are run on a schedule and have broader coverage of pipelines. Teams have a data health dashboard they use to view issues, troubleshoot and direct others in the organization to learn about up-to-date status of data. Examples:
- Tracking metrics about dimensions and measures, storing in a time-series database to track trends and changes
- Monitor and enforce schema in the ingest process
#4 Scalable: the data team draws on concepts from dev ops and institutes a staging environment, reusable components for validation, and/or hard and soft alerts for data errors. There is substantial coverage of mission-critical data and the team is on top of issues before they propagate downstream. Examples:
- Anomaly detection to detect issues in all key metrics
- Tooling to allow every job and table to easily be monitored and tracked for quality
In a recent poll I conducted among ~50 data professionals, more than 60% indicated they are currently in the earlier stages of the data reliability journey, however they are taking concrete steps in their roadmap to move up the curve.
Where are you in your data reliability journey, and where do you want to be by the end of 2019?
Talk to us by scheduling open time with the form below.
Our promise: we will show you the product.
Read more posts.