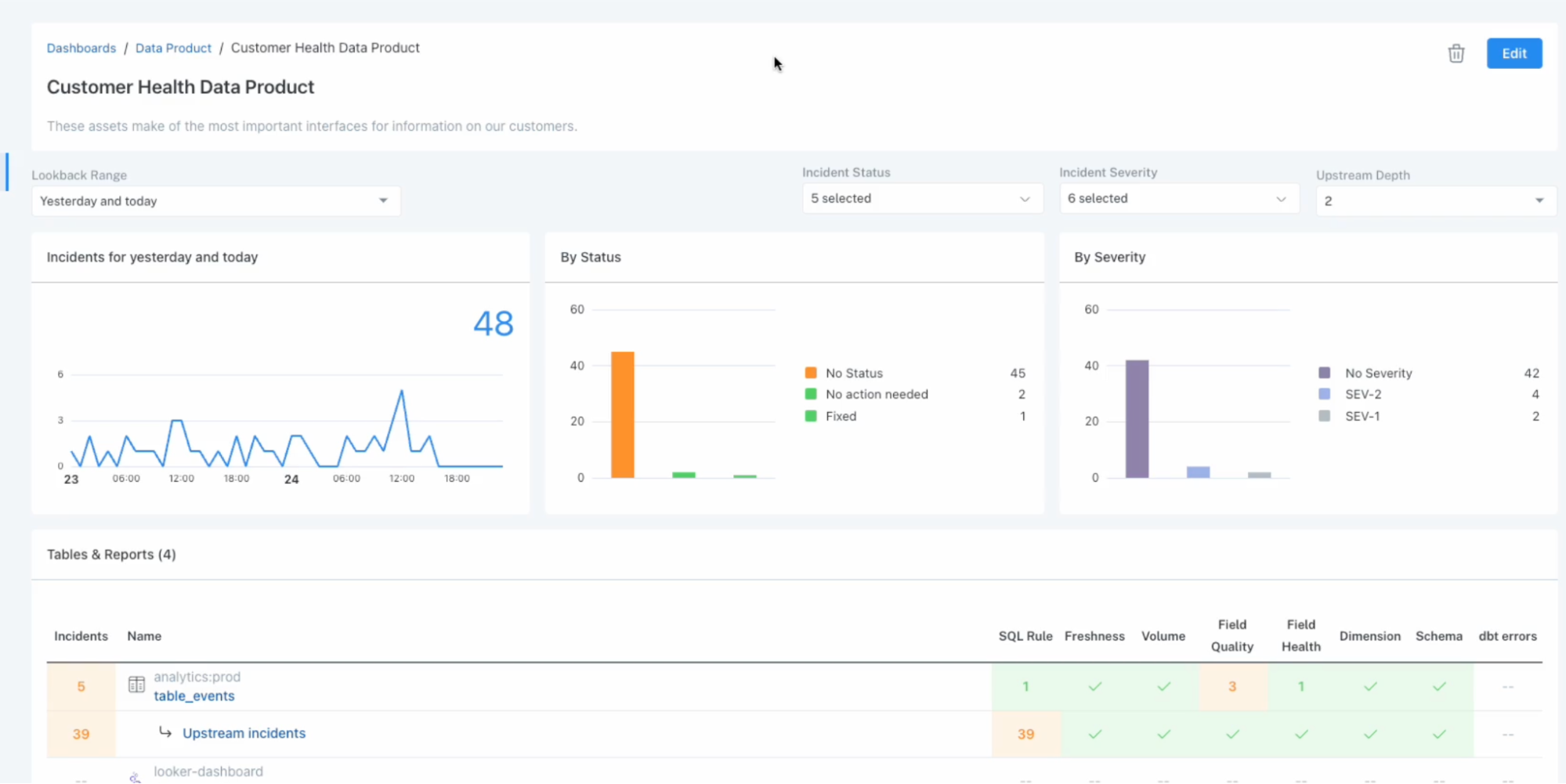
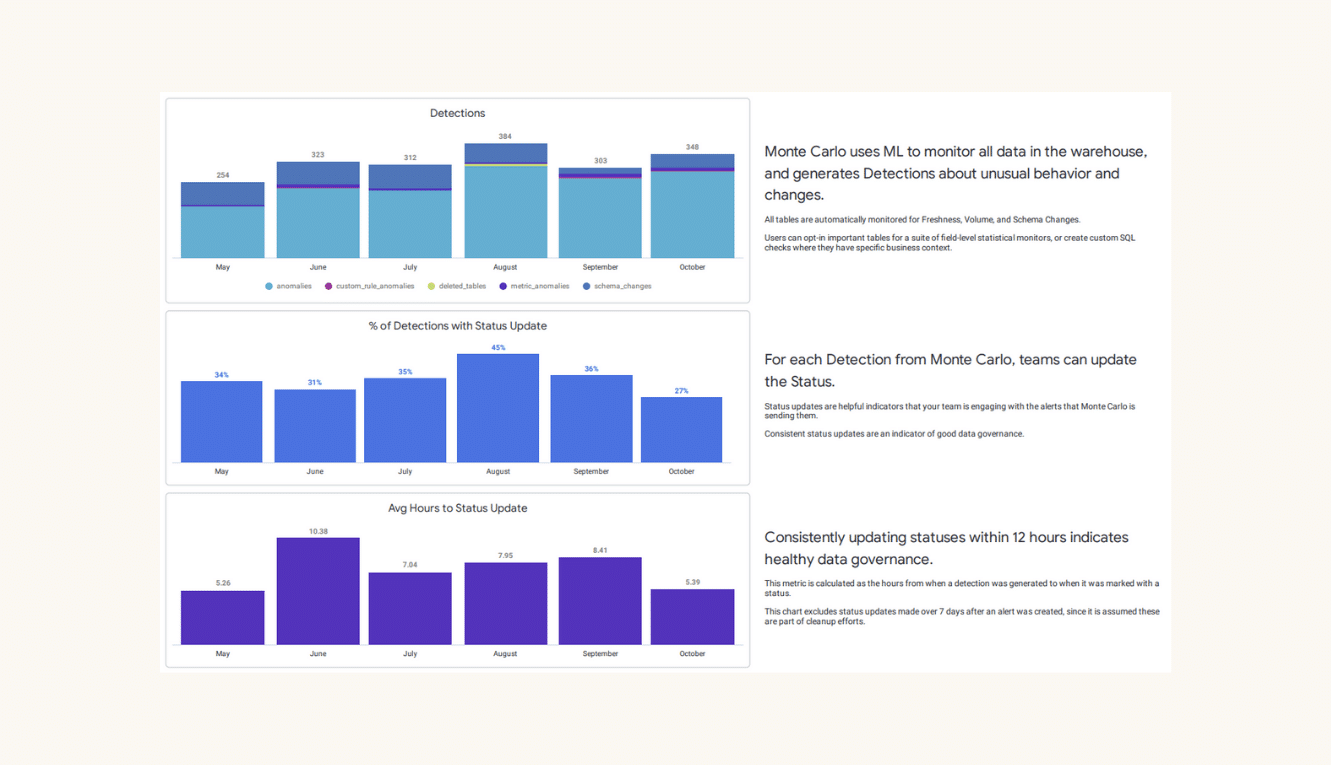
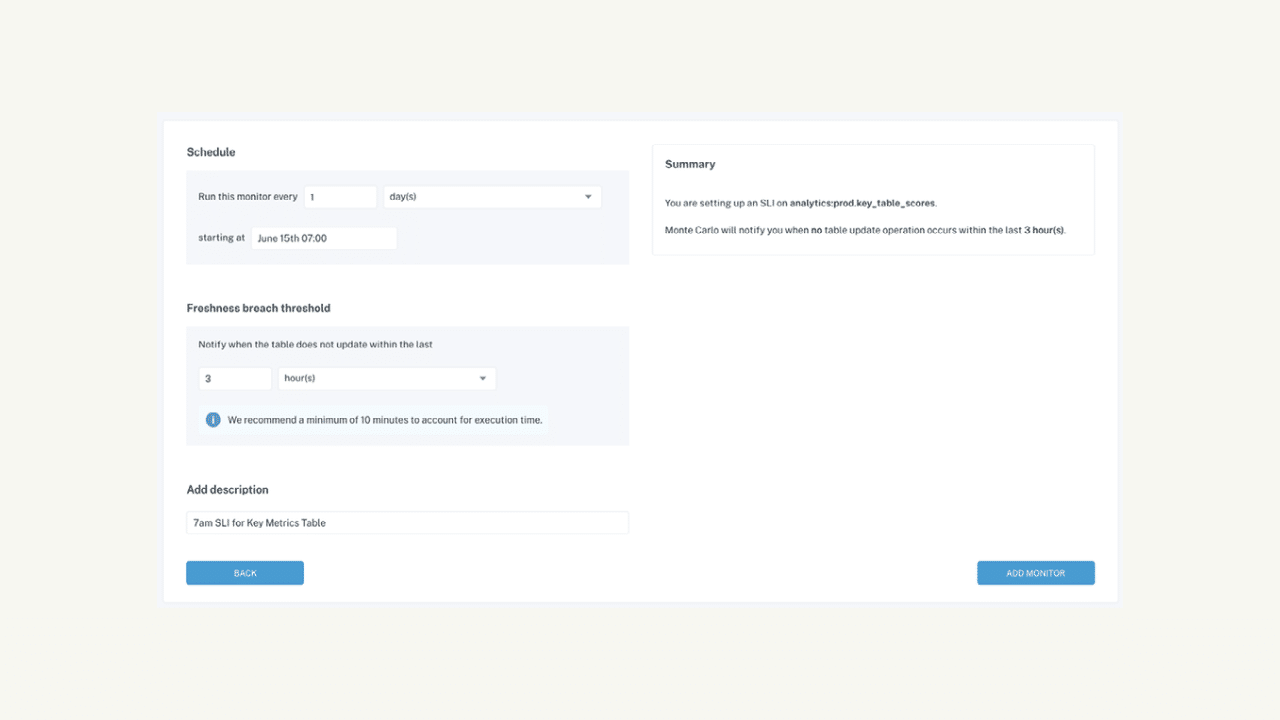
Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Celebrating the New Pioneers of Data Reliability


Will Robins
Will Robins is a member of the founding team at Monte Carlo.
It would be an understatement to say your company is bullish on data.
Your CEO can’t stop talking about her new Tableau dashboard, a report that tells which of your products are “stickiest” with customers. It didn’t take much convincing to sell your CTO on Snowflake. And your entire data engineering team is all in on this “data as code” movement.
The flip side of this data-driven coin: your stakeholders (CEO and CTO included) ping you nearly every other hour to ask you: “is my data up-to-date?”, “who owns this report?”, and even “why is my data missing?”
As data systems become increasingly distributed and complex to support additional use cases, the opportunity for data downtime only grows. In fact, according to research published by Dun & Bradstreet, nearly 20 percent of companies have lost a customer due to incomplete or inaccurate information. https://www.montecarlodata.com/blog-the-rise-of-data-downtime/
The good news? There’s hope in this fundamental layer of the modern data stack: data observability. With data observability, data teams can achieve trust in their data, meaning relieved data engineers and analysts, happy execs, and no data downtime.
At Monte Carlo, we’re honored to work with companies who are forging the path to data reliability, the first step towards accelerating the adoption of data at scale.
To celebrate the pioneers of this new category, we’re honored to highlight this select group of data leaders and early adopters.
These enterprises are charting a new course for what it means to be truly data-driven in today’s world: having trusted, reliable data in industries such as B2B SaaS, digital marketplaces, financial technology, eCommerce, consumer technology, and retail.
B2B SaaS
PagerDuty

PagerDuty is the world’s leading digital operations platform for full-stack incident response and on-call management. As an organization, they are dedicated to helping professionals achieve reliability across their software and data ecosystems. Data informs every business decision, from customer support to feature development, and most recently, how to support pricing plans for organizations most affected during COVID-19.
When migrating to Snowflake, PagerDuty wanted to understand the health of their data pipelines through fully automated data observability. To achieve this data trust, they turned to Monte Carlo.
“Powered by real-time data, PagerDuty’s Digital Operations management platform enables over 13,000 businesses across the world to hit their uptime SLAs for application reliability. When it comes to ensuring the uptime of PagerDuty’s business data, our Data Engineering & Business Insights team applies similar principles of AI-driven observability and monitoring to stop data quality issues in their tracks. With Monte Carlo, my team is the first to know when data breaks so that we can manage that incident lifecycle through Pagerduty, in turn allowing us to prevent and resolve data downtime before it impacts the business,” said Manu Raj, Senior Director of Data Platform and Analytics at PagerDuty.
Hotjar

For Hotjar, data powers a wide variety of use cases, from crafting the ideal marketing campaign to creating delightful product features. Hotjar’s data engineering team supports over 180 stakeholders and their data needs, from deploying models and building pipelines to keeping tabs on data health.
To ensure that their data pipelines are reliable and trustworthy, Hotjar relied on dbt for testing and transforming their data before it entered their business intelligence layer. However, this approach led to frequent issues with alerting around pipeline delays. To accommodate for this gap and to supplement their testing strategy, Pablo Recio and the rest of Hotjar’s data engineering team chose to implement Monte Carlo for end-to-end data observability, monitoring, and field-level lineage, notifying them of critical issues in their pipelines and saving them 3x on infrastructure costs.
“Monte Carlo gives us the power to know what’s going on with our data at any given point in time so we can ask the right questions when data downtime strikes, for instance ‘we think something’s wrong here, did you change anything, or is this expected?’” said Pablo Recio, a Data Engineer, Hotjar.
Consumer Technology
Jimdo Data
Jimdo, a German website builder and all-in-one hosting solution, allows business professionals to effortlessly create a website or store for their small business. With data driving the product roadmap, executive decision making, and even go-to-market strategy, Jimdo couldn’t afford to have data downtime. To make data reliable for stakeholders and ensure end-to-end data trust across their business, Jimdo turned to Monte Carlo.
“The data landscape is at a turning point. We have unprecedented volumes of data and incredible amounts of computing power but also constantly increasing complexity. Ironically, the more data we have, the murkier the picture seems to become. Nowhere is this more true than when data teams try to measure their own performance. Are tables up to date? Is the data safe to use? Is this anomaly a business outcome or a data pipeline problem?,” said Gordon Wong, Interim CDO of Jimdo and Principal Solution Architect.
“What excites me about Monte Carlo is their vision for making the delivery of data more reliable and transparent through observability. The platform’s machine learning parses queries, logs, metadata, and other contextual information in such a way that provides the trifecta of data trust: automatic field-level lineage, data discovery, and anomaly detection right out of the box. This end-to-end solution enables us to both reactively fix data pipeline problems before they impact users and proactively target real system improvement. The net impact is unblocked teams, happy execs, and lower-cost data platforms.”
Financial Technology
Pie Insurance
Pie Insurance is responsible for underwriting the risk of thousands of small businesses, making data fidelity and reliability a top priority. Pie relies on high-quality third-party data combined with predictive analytics to quote a small business owner’s workers’ compensation policy in minutes, delivering seamless experiences for customers. The significance of these insights means that Pie—and its customers—are dependent on this data to be accurate and reliable at all times. Pie Insurance chose Monte Carlo’s end-to-end approach to data observability and lineage to uncover schema, distribution, and freshness issues that would have otherwise gone unnoticed, costing them time, money, and trust in their data.
“To power product growth and deliver exceptional user experiences across our suite of insurance offerings, we partnered with Monte Carlo for automatic, end-to-end data observability. Within minutes, we were up and running with Monte Carlo and within days, the platform was uncovering critical schema and pipeline changes that would have impacted the business if left undetected,” said Matt Frazier, Chief Analytics Officer at Pie Insurance.
Clearcover
Clearcover is dedicated to making it easy and secure for car owners to save time and money on their insurance. Their artificial intelligence data-driven platform relies on high-quality data to make coverage recommendations for customers. To ensure that the data enabling their insight-driven decision-making is as reliable as possible, Clearcover chose Monte Carlo to provide data observability, monitoring, and end-to-end lineage across our Snowflake and Tableau data stack.
“With Monte Carlo’s ML-powered anomaly detection and field-level lineage, our data team can effortlessly manage and triage data incidents before they affect downstream consumers, and proactively understand the impact of these issues so we can correct course. Now, our data engineers and analysts can collaborate to achieve data trust at each stage of the data pipeline, from ingestion to analytics. Their future is bright and we couldn’t be more excited to pioneer data reliability with them!,” said Braun Reyes, Senior Data Engineer, Clearcover.
E-commerce
Red Ventures UK
Data is the foundation that powers machine learning and business analytics efforts for Red Ventures UK, a global suite of leading consumer marketplace brands. Because of the role data plays in their organization, the data team at Red Ventures needs to be the first ones to know when something is wrong with the data, rather than receiving a frantic Slack ping or text about “broken dashboards” and “missing values.” To achieve end-to-end data reliability across their portfolio of companies, they turned to Monte Carlo’s data observability platform.
“RVU is committed to delivering reliable and accurate data products for teams across our portfolio of companies. With Monte Carlo’s end-to-end data observability, our data engineers and analysts can automatically and collaboratively detect, alert on, and resolve data downtime before it becomes a problem for the business. Their ML-enabled monitors make it easy to keep tabs on hidden data issues in our pipelines, allowing us to trust our data at each stage of its life cycle,” said Siddharth Dawara, Principal Engineer, at Red Ventures UK
Media & Entertainment
Kolibri Games
Berlin-based Kolibri Games has had a wild ride, rocketing from a student housing-based startup in 2016 to a headline-making acquisition by Ubisoft in 2020. While a lot has changed in five years, one thing has always remained the same: the company’s commitment to building an insights-driven culture based on accurate and reliable data.
To achieve end-to-end data reliability as they move towards a self-serve, decentralized data architecture, António Fitas, Head of Data Engineering at Kolibri, chose to partner with Monte Carlo. With data observability, the team has full knowledge of the unknown unknowns in their data pipelines, allowing them to automatically identify, root cause, and resolve data issues before they affect downstream analytics.
“Data is integral to Kolibri Games’ DNA, powering our product roadmap, marketing strategy, and growth operations. With over 100 million unique events produced per day across 40 different event types, our games generate an unprecedented amount of data, and in order to trust it, we need to know when incidents arise in our pipelines and dashboards. After trying to build their own custom solution for data monitoring, we realized it would require a full-time person to build a framework to extend it to different use cases and monitor all data assets. Monte Carlo helped us achieve data reliability by monitoring the quality of all of the data in the data warehouse, and providing extra capabilities about understanding the end-to-end lineage and root cause analysis of data issues to speed up troubleshooting and incident resolution,” said António Fitas, Head of Data Engineering at Kolibri Games.
Digital Marketplaces
AutoTrader
Manchester-based Auto Trader is the largest digital automotive marketplace in the United Kingdom and Ireland. For Auto Trader, connecting millions of buyers with thousands of sellers involves an awful lot of data.
The company sees 235 million advertising views and 50 million cross-platform visitors per month, with thousands of interactions per minute—all data points the Auto Trader team can analyze and leverage to improve efficiency, customer experience, and, ultimately, revenue. Data also powers business outcomes from advertising optimization to reporting to ML-powered vehicle valuations. To achieve data trust at scale, Edward Kent, Principal Developer, and his data engineering team turned to Monte Carlo’s end-to-end data observability platform.
“Before Monte Carlo, we needed to know in advance what we wanted to monitor, and go through the manual process of setting up dbt and SQL tests. AutoTrader has hundreds of data models defined and hundreds of tables built daily, making this manual set-up time and resource-intensive. With Monte Carlo, we were able to achieve end-to-end data trust off the bat without us having to put in that effort and know what we needed to test for. With Monte Carlo’s schema, freshness, and volume checks, we have far more visibility into what’s going on with our data than we’ve ever had before. Previously, a lot of these issues would have been caught and reported by data consumers are now getting automatically flagged. From a tracking perspective, this visibility is hugely important for us as we move towards decentralized data ownership and true data reliability,” said Edward Kent, Principal Developer, Auto Trader.
Retail
Resident
Resident, a house of direct-to-consumer mattress brands, relies on data to drive marketing decisions and spend, with over 20 marketing connections supporting lead and customer tracking, segmentation, and retail analytics. In 2019, the company suffered from unreliable data and strained relationships between teams because stakeholders weren’t able to access the most up-to-date data they needed to make decisions. Beyond the company’s internal relationships, the customer experience was hurting as well, with bad data leading to customers receiving emails that weren’t relevant to them.
As Daniel and her team began to understand what they needed, rather than building out a custom system, Resident began using Monte Carlo to handle real-time monitoring and alerting, as well as lineage
“Before Monte Carlo, I was always on the watch and scared that I was missing something. I can’t imagine working without it now. We have 10% of the incidents we had a year ago. Our team is super reliable, and people count on us. I think every data engineer has to have this level of monitoring in order to do this work in an efficient and good way,” said Daniel Rimon, Head of Data Engineering, Resident.
Cheers to the pioneers of Data Reliability!
The promise of Data Reliability extends far beyond these select groups of enterprises, affecting companies across healthcare, banking, hospitality, education, and literally every other space that relies on data to innovate and maintain a competitive edge.
The best part of this journey? Working with data leaders across the space to pioneer the Data Observability category. With the right approach to data trust, teams across industries can eliminate Data Downtime and unlock the full potential of their data.
Interested in joining the Data Reliability movement? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Correction issued Saturday, Sept. 4, 2021: An earlier version of this article stated that “data downtime caused 1 in 5 companies to lose a customer,” instead of “20 percent of companies.”
Read more posts.