Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Cost of Bad Data Has Gone Up. Here Are 8 Reasons Why.


Will Robins
Will Robins is a member of the founding team at Monte Carlo.
You may not have heard the term data downtime, but I’m willing to bet you’ve experienced it and the cost of bad data firsthand.
Urgent ping from your CEO about “missing data” in a critical report? Duplicate tables wreaking havoc in your Snowflake warehouse, all titled some variation of “Mikes_Table_GOOD-V3.”? Or, perhaps you’ve unintentionally made a decision based on bad data from last year’s forecasts?
Data downtime is when data is missing, erroneous or otherwise inaccurate. It intentionally recalls the early stages of the internet when websites would go down with what today would be alarming frequency.
It makes sense now looking back on it. Not only were there infrastructure challenges, but not that many people were using the web and sites were not nearly as valuable. As that changed with the rise of the cloud, e-commerce and SaaS, ensuring reliability became mission critical to a business and site reliability engineering (SRE) was born.
Data is at a similar moment in time. Technologies are advancing, companies are moving to the cloud, and data is becoming more widespread and valuable than ever before.
The corollary to this is that as data becomes more valuable, the consequences of poor data quality become more severe. The best practices, technologies, and investment that were sufficient just a year or two ago will now jeopardize an organization’s ability to compete.
Through 2025, 80% of organizations seeking to scale digital business will fail because they do not take a modern approach to data and analytics governance according to Gartner.
In this post, we will cover 8 reasons why the cost of bad data is rising, including:
- Data is moving downstream
- Data stacks are becoming more complex
- Increased data adoption
- Expectations of data consumers are increasing
- Data engineers are harder to find
- Data quality responsibilities are becoming distributed
- Crumbling of the cookie
- Data is becoming a product, and it’s super competitive
Let’s get into it.
Data is moving downstream
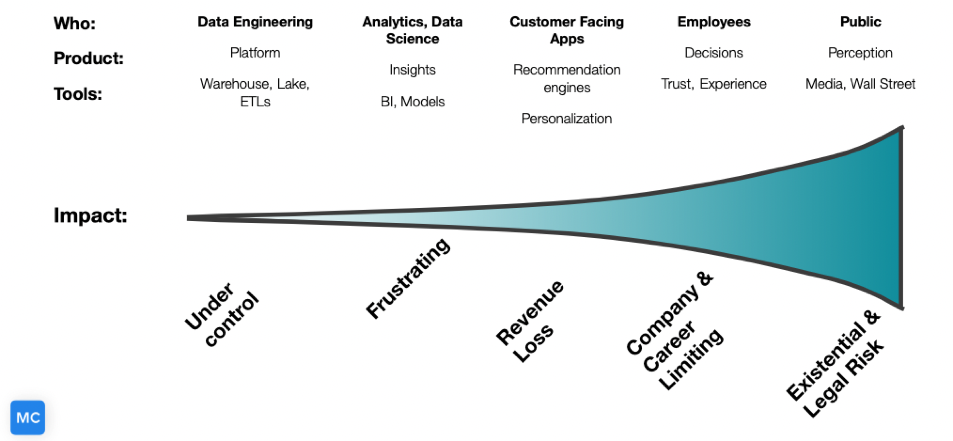
If bad data is caught by a data engineer, they are a hero. No harm, no foul. If bad data is caught by the general public, there could be reputational or legal repercussions depending on the situation.
Each stage also acts as a filter preventing bad data from moving downstream. The challenge is there are multiple trends in data currently that are accelerating the pace of data moving downstream from data democratization, data products, reverse ETL, and more.
Data stacks are becoming more complex
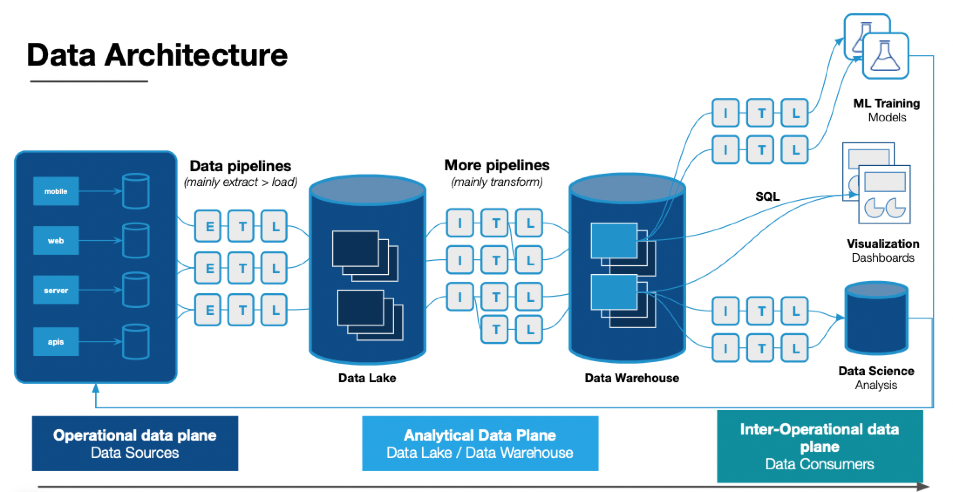
The further downstream that bad data travels, the more expensive the fix. It is much easier and quicker to have a data engineer troubleshoot an ETL pipeline than for a data scientist to re-train a machine learning model that has been fed bad data.
It’s not just the remediation that is expensive either. As companies increasingly rely on complex data assets to help execute business decisions, the opportunity costs of bad data rise as well.
For example, I spoke with an investment company with a machine learning model that would buy bonds automatically when they met certain criteria. Schema errors would take the model offline for days or weeks, and as a result ground this part of their business to a standstill. Yikes.
As data stacks become more complex, there are also more data “handoffs” introducing the opportunity for more issues. For example, one gaming company I spoke with noticed drift in their new user acquisition data.
The social media platform they were advertising on changed their data schedule so they were delivering data every 12 hours instead of 24. The company’s ETLs were set to pick up data only once per day, so this meant that suddenly half of the campaign data that was being sent to them wasn’t getting processed or passed downstream, skewing their new user metrics away from “paid” and towards “organic.”
Increased data adoption

Chances are your organization has more data consumers that are more data dependent than just a year ago. Businesses have recognized the power of data democratization and are moving quickly to make their organization’s more data driven.
According to a Google Cloud and Harvard Business Review report, 97% of surveyed industry leaders believe organization-wide access to data and analytics is critical to the success of their business.In fact, more than half of AutoTrader UK’s employees regularly engage with the data in their Looker dashboards at least once a month.
This is an awesome trend. However, more data consumers and more data analysts mean more people sitting on their hands when data downtime strikes.
Expectations of data consumers are increasing

And they have higher expectations than ever. They are accustomed to leveraging SaaS products that are guaranteeing 5 9’s of availability, meaning they are down less than 12 minutes a year. To be honest, I don’t know any data teams clearing that bar.
Unfortunately, most data teams are evaluated based on a feeling. Either data consumers and executive leadership “feel” the team is doing well or poorly. That’s because nearly 60% of organizations don’t measure the annual financial cost of bad data, according to Gartner.
With high data consumer expectations and little qualitative data measuring performance, data downtime has severe consequences not just for organizations but for data teams as well.
Data engineers are harder to find

One of the most frequent laments I hear from data teams is how difficult it is to hire in today’s extremely competitive labor markets. Their frustration is palpable. They have gone through the long, arduous process of obtaining headcount, but they can’t find any data engineers to take the job.
This isn’t just anecdotal evidence either. The Dice 2020 Tech Job Report said data engineer was the fastest growing job in technology with a 50% year-over-year growth in the number of open positions and the 2022 Report has the average salary as $117,295.
Data engineers are quickly becoming one of the most valuable assets. Taking them offline to fix downtime is expensive, and doing it repeatedly risks them deciding to leave to where they will work on more interesting projects.
Data quality responsibilities are becoming distributed
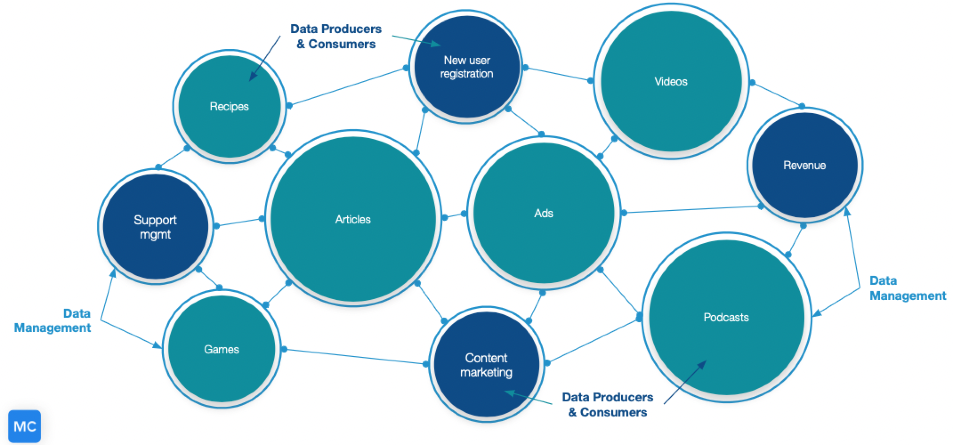
One of the hottest concepts in data right now is the data mesh, which federates data ownership among domain data owners who are held accountable for providing their data as products, while also facilitating communication between distributed data across different locations.
This has the advantage of bringing data teams closer to the business and understanding the purpose of all relevant data operations, however it by its very nature also diffuses responsibility.
A decentralized setup puts a larger burden on clear communication and crisp processes. There is not one inbox or Slack channel to frantically ping when things are going wrong, and that’s scary.
Without strong processes, the diffusion of responsibility can extend the time it takes to resolve bad data or data downtime when these problems cross domains.
Crumbling of the cookie
Director of Product Management at Snowflake, Chris Child, recently made an interesting point in his conversation with Monte Carlo CEO Barr Moses. He pointed out that with tightening regulations such as GDPR and the industry’s move away from the cookie, companies are going to become more reliant on first versus third-party data.
That means they will need to collect more data, which will become more valuable since they can no longer rely on Google algorithms to help their ads find the right consumers. Therefore, data downtime is starting to have a larger impact on marketing operations and the cost of bad data is rising.
Data is becoming a product, and it’s super competitive

Data teams are creating sophisticated data products that are quickly becoming part of the customer offering and unlocking new value for their companies.
In some industries, this has become super competitive. If your team is not producing actionable insights, you will quickly get outperformed by someone who is.
I see this most frequently in the media space, where data has become a complete arms race. The scale of data teams and the investment in them is astronomical. It has been breathtaking to watch these companies move from hourly batching, to 15 minutes, to every 5 minutes, and now starting to stream.
There is no room for bad data in this environment. During your data downtime, someone else is publishing the scoop, getting clicks, and gaining valuable insights into their audience.
An ounce of treatment is worth a pound of pain
When you consider the increasing cost of bad data, and that most organizations have more data quality issues than they think, increasing your investment in data quality seems like a smart move to make.
Some data teams are very perceptive when it comes to internal signals that it’s time to invest in data quality (from migrating to a cloud data warehouse like Snowflake or Redshift to having the CEO yell), but external drivers like the ones mentioned above can get lost in the shuffle.
I recommend taking a proactive approach. Consider how you can invest in your people, processes and technologies to mitigate the rising cost of bad data.
Interested in learning more about how data observability can help you avoid the rising cost of bad data? Reach out to Will Robins and book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.