Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Scaling Data Trust: How AutoTrader UK Migrated to a Decentralized Data Platform with Monte Carlo

Will Robins
Will Robins is a member of the founding team at Monte Carlo.
Leading companies are pioneering a shift into greater data democracy through decentralized data platforms—but without the right governance and visibility in place, data quality can suffer and data trust can erode. That’s where data observability comes in.
Here’s how the Data Engineering team at Auto Trader achieves automated monitoring and alerting while decentralizing responsibility and increasing data reliability with Monte Carlo.
Manchester-based Auto Trader is the largest digital automotive marketplace in the United Kingdom and Ireland. For Auto Trader, connecting millions of buyers with thousands of sellers involves an awful lot of data.
The company sees 235 million advertising views and 50 million cross-platform visitors per month, with thousands of interactions per minute—all data points the Auto Trader team can analyze and leverage to improve efficiency, customer experience, and, ultimately, revenue. Data also powers business outcomes from advertising optimization to reporting to ML-powered vehicle valuations.
For Principal Developer Edward Kent and his Data Engineering team, collecting and processing this enormous amount of data is no small feat. Recently, the data team has been focused on two key missions.
“We want to empower Auto Trader and its customers to make data-informed decisions,” said Edward, “and democratize access to data through a self-serve platform.”
These ambitious goals coincided with a migration to a modern, cloud-based data architecture—meaning Edward and his team had to simultaneously make data more accessible to more teams, while building trust in data quality.
The challenge: building trust and empowering self-serve data
“As we’re migrating trusted on-premises systems to the cloud, the users of those older systems need to have trust that the new cloud-based technologies are as reliable as the older systems they’ve used in the past,” said Edward.
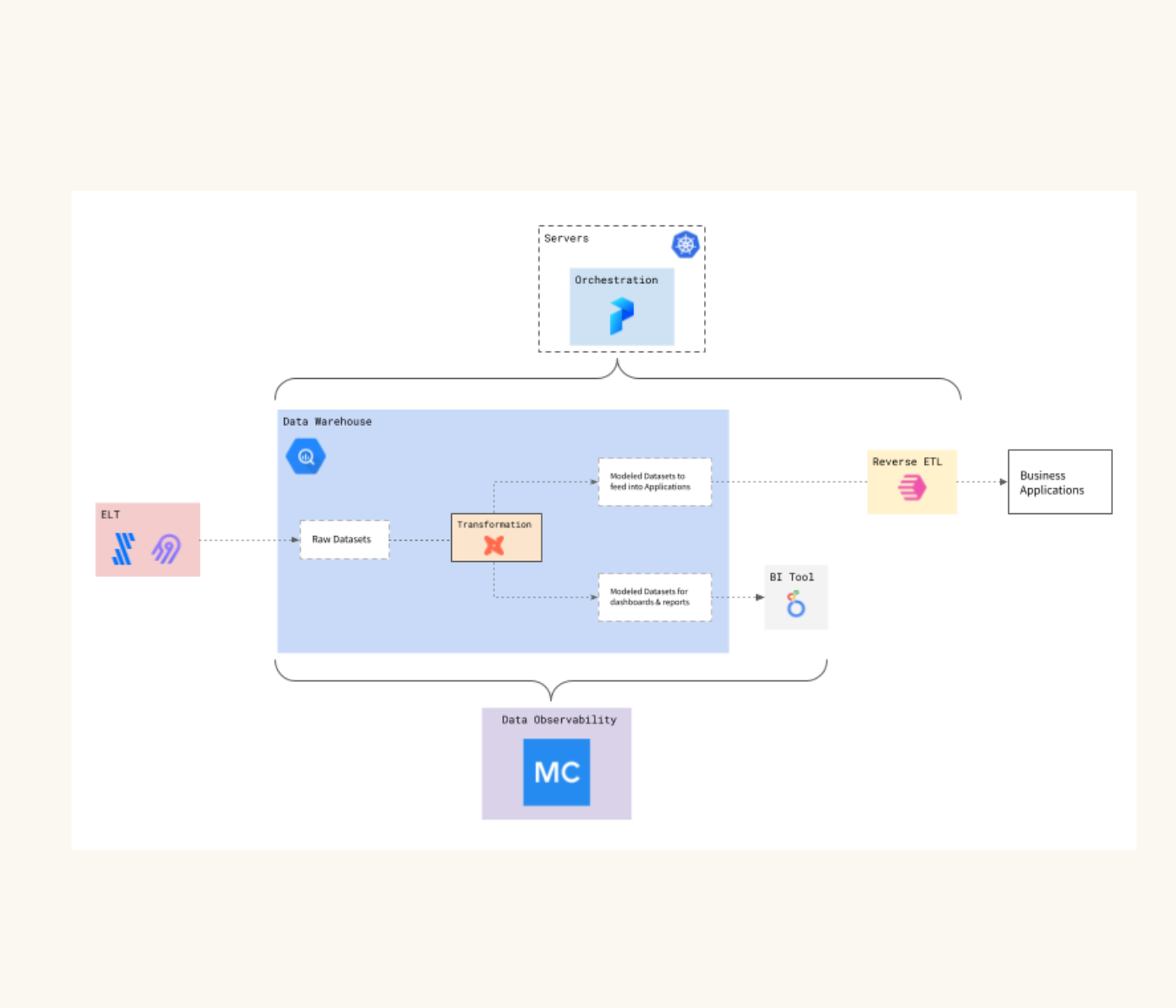
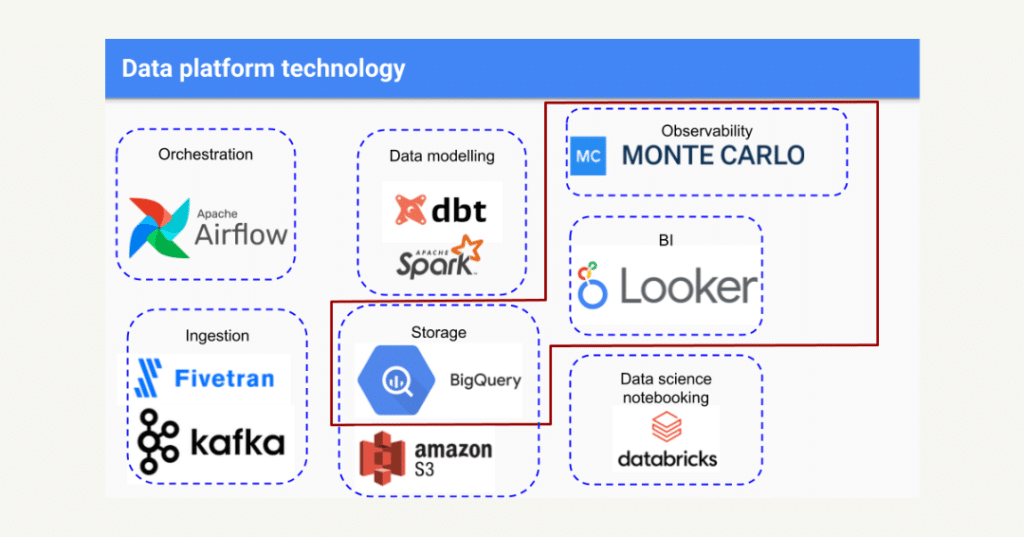
Today, Edward and his team have a robust data stack. They ingest data through Kafka and Fivetran, handle orchestration and scheduling in Apache Airflow, store data in BigQuery and Amazon S3, use dbt and Apache Spark for modeling, Databricks for data science notebooking, and surface data to internal consumers through Looker.
And there are a lot of eyeballs on that data. Over 500 active users (more than 50% of all Auto Trader employees!) are logging in and engaging with data in Looker every month, including complex, higher-profile data products such as financial reporting. Of course, with massive amounts of data and a multi-layered tech stack comes a multitude of opportunities for data pipelines to break—and those incidents were almost always noticed by one of those 500 data consumers first.
Edward and his team needed to address data downtime (periods of time when their data was partial, erroneous, or otherwise inaccurate) to improve trust, but at the same time, were functioning as a bottleneck for the rest of the company. Their centralized team of data engineers handled everything that touched their data operations, from requests to build new pipelines and reports to urgent calls to investigate data quality issues. The approach didn’t scale and resulted in a backlog of requests, which led Edward and his team to develop a plan to build an abstracted, self-serve platform for business consumers to use on their own.
“Rather than having a single data team that does everything, we’d like to give teams the platform-level capabilities and autonomy to build their own data products,” said Edward. “Ideally, we’d like to have teams manage everything in the life cycle of their data pipeline. So everything from ingestion to modeling to alerting, et cetera. And so it’s in this context that we’d like to provide data observability as a platform capability.”
Enter Monte Carlo.
The solution: Incorporate Monte Carlo for data observability
We partnered with Auto Trader to integrate the Monte Carlo data observability platform into their existing data platform. Specifically, they wanted to add a layer of monitoring, alerts, and lineage on top of BigQuery and Looker—the most highly visible layers of their data stack.
“It’s more important for us than ever before that the data we’re serving out is correct, accurate, and up-to-date,” said Edward. “So that’s where the concept of data observability comes in.”
Auto Trader uses Monte Carlo to perform volume and freshness checks, as well as alerts on schema changes, on all tables in BigQuery. Edward’s team also opts-in dozens of critical tables for a suite of ML-driven statistical checks, making it easy to have column-level confidence without the cumbersome process of defining thresholds. Monte Carlo has also helped them understand all the dependencies in their data. “We found it quite difficult to understand what tables in BigQuery are surfaced in which reports in Looker, and vice versa,” Edward said. “The lineage tracking across those two systems was really powerful for us.”
Outcome: Incident tracking that builds trust
Before Monte Carlo, the data engineering team would find out about data quality issues when internal consumers would send them Slack messages about Looker reports that didn’t seem quite right.
The data team would then have to a) investigate if there was a genuine issue; b) try to determine the root cause; c) figure out which tables or dashboards were downstream and which consumers would be affected; and d) finally, track down and notify relevant stakeholders to communicate that an issue had been detected, estimate when it would be resolved, and follow up again once the problem was fixed. Edward described the process as “reactive, slow, and unscalable.”
Now, with Monte Carlo, Edward’s team receives a Slack notification when a possible incident is detected.
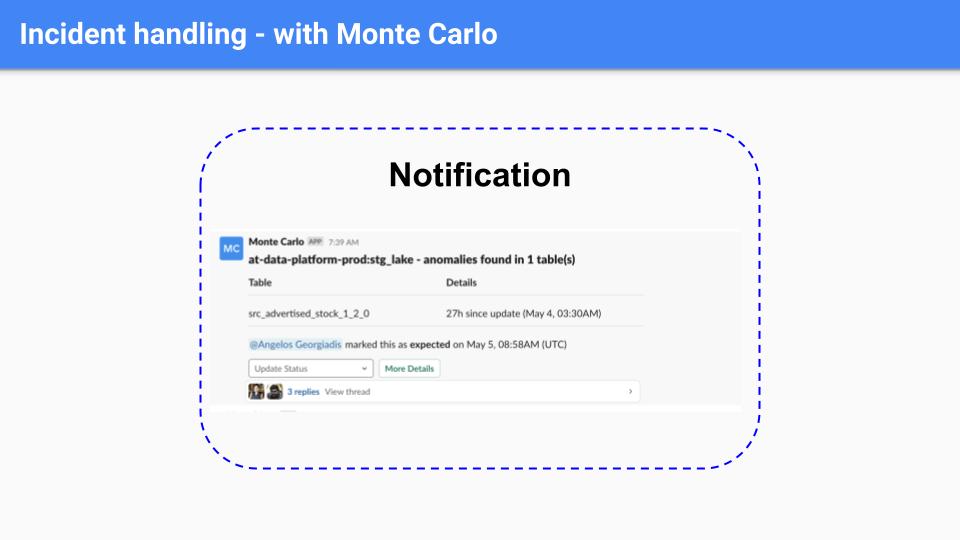
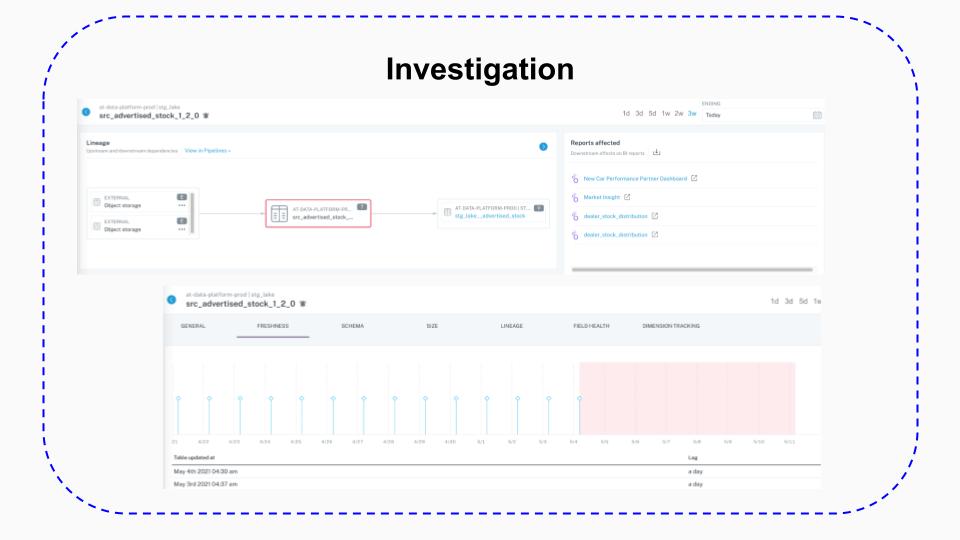
They can investigate issues much more quickly thanks to automated, end-to-end lineage, which helps data engineers understand the possible upstream and downstream impacts down to the field level, as well as provides visibility into freshness, volume, and distribution changes which helps them look at update patterns and notice suspicious changes.
With Monte Carlo, communication is also streamlined. Edward’s team doesn’t have to track down stakeholders—again, thanks to lineage—and can send notifications about issues and resolutions through Monte Carlo to the relevant teams’ Slack channels.
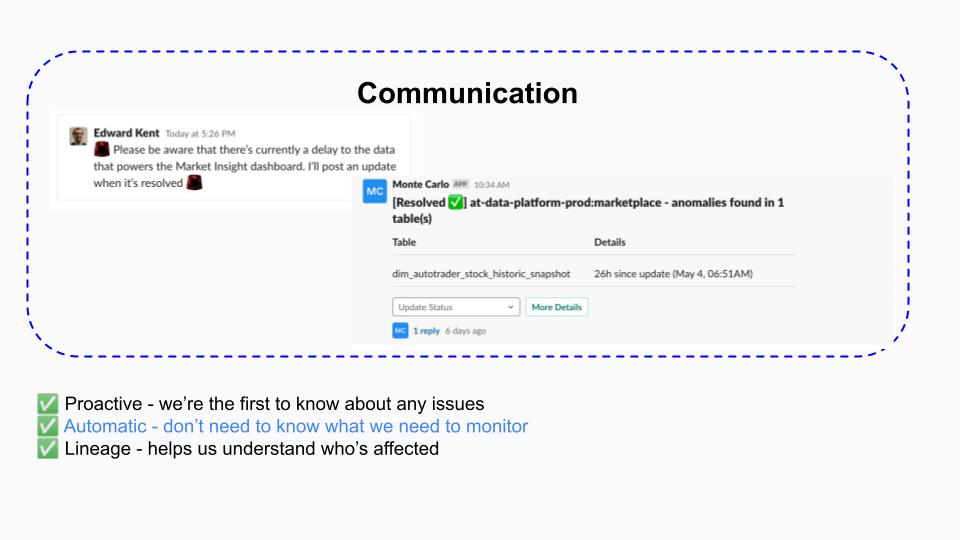
With automated monitoring and alerting in place, and lineage speeding up incident time-to-resolution, the data engineering team is building greater trust with their stakeholders by proactively tackling data issues before downstream consumers even notice something’s gone wrong.
Outcome: Scalable monitoring and visibility into “unknown unknowns”
Edward also credits Monte Carlo for its machine-learning powered monitoring.
“We don’t need to know what we need to monitor in order to start getting value,” Edward said. “Monte Carlo can start looking for patterns and will alert us to any anomalies and deviations from those patterns.”
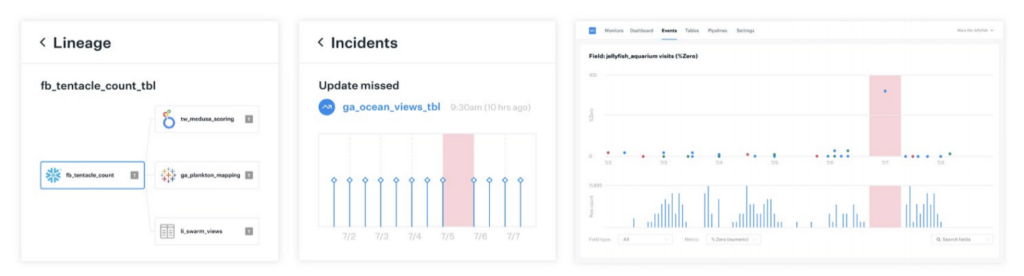
For example, Monte Carlo spotted an unexpected deletion of 150,000 rows in a table where deletions are rare. A data engineer was able to dig into Monte Carlo and noticed there was a deletion to a table that typically only saw additions. Using lineage tracking, they could look at what was upstream of that data, see that it came in through ETL from an external source, and go and check with the data owner to see if that was legitimate and intended, or if something had gone wrong.
“In this case, no action was needed,” said Edward. “But it’s really valuable to know that this sort of thing is happening with our data, because it gives us confidence that if there were a genuine issue, we’d find out about it in the same way.”
The data engineering team uses custom SQL rules and dbt for manual testing, but due to the scale of their data, relies on Monte Carlo as the bedrock of their monitoring so they can catch ‘unknown unknowns’.
“Whether it’s custom SQL rules or dbt tests, you have to do that upfront configuration,” said Edward. “You have to know in advance what it is you’re going to monitor, and go through the process of setting it up. For us, we have hundreds of data models defined and hundreds of tables built daily. We wanted something that would effectively get this off the ground and running without us having to put in that effort. The schema checks, the volume checks, the freshness checks that Monte Carlo offers delivers on that.”
Outcome: Empowering Auto Trader’s self-service data platform
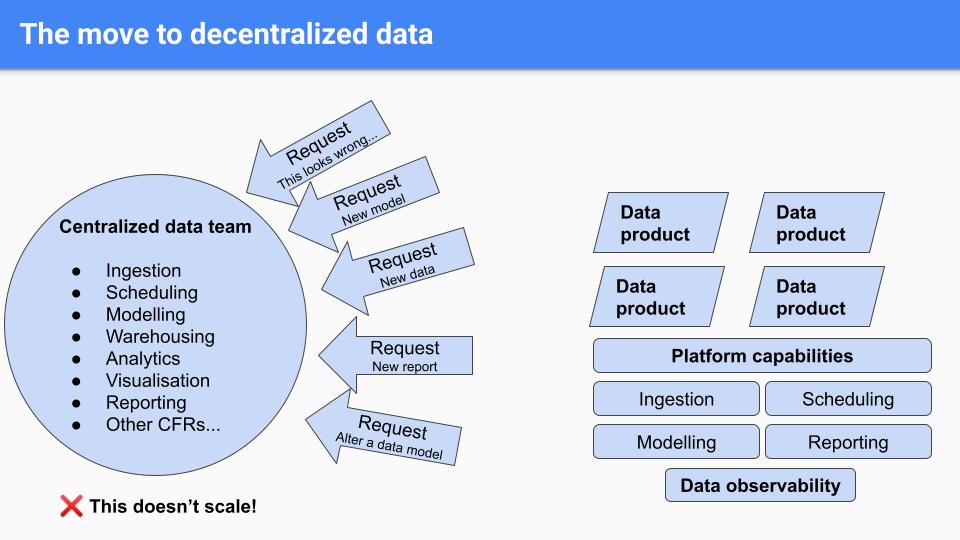
Monte Carlo also supports Auto Trader’s transition to a decentralized, self-serve data program—without compromising on data quality.
Under this new model, decentralized alerts are routed to the appropriate team’s alerts channel. Edward and his team require data ownership and alerting to be defined as metadata alongside other attributes in their dbt .yaml file, so product teams who own specific datasets will automatically receive Monte Carlo alerts to their own channels.
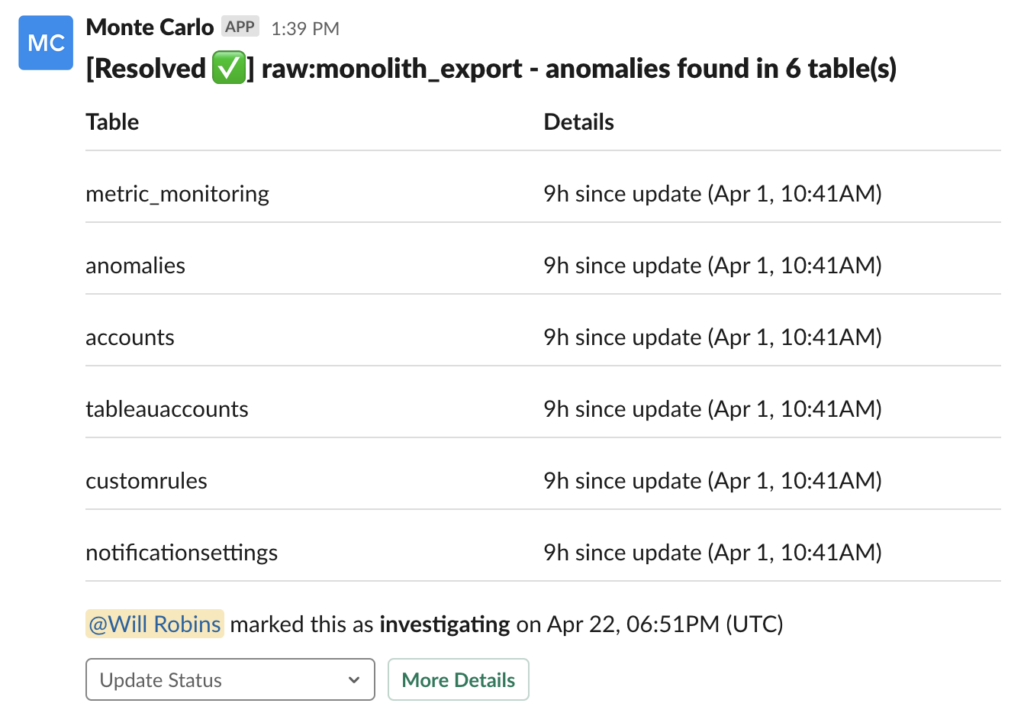
“Decentralized data ownership means decentralized responsibility for data observability,” said Edward. “Monte Carlo helps us provide this platform capability.”
The impact of data observability at Auto Trader
As Auto Trader seeks to build trust in data while opening up access, data observability is key to ensuring data remains accurate and reliable.
“We have far more visibility into what’s going on with our data than we’ve ever had before,” said Edward. “Previously, a lot of these issues would have been caught and reported by data consumers are now getting flagged by Monte Carlo. From a tracking perspective, this visibility is hugely important for us as we move closer towards a decentralized data platform.”
Interested in learning how data observability could improve your team’s visibility, response time, and efficiency? Reach out to Will Robins and book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.