Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Observability 101: Everything You Need to Know to Get Started


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
What is data observability and does it make sense for your stack? Here’s your go-to guide to starting on the path towards data trust at scale.
One of the most common questions I get from customers is: “How do I get started with data observability?” And for good reason. 🙂
Emerging as a layer in the modern data stack just over a year ago, data observability refers to an organization’s ability to fully understand the health and reliability of the data in their system. Traditionally, data teams have relied on data testing alone to ensure that pipelines are resilient; in 2021, as companies ingest ever-increasing volumes of data and pipelines become more complex, this approach is no longer sufficient.
Don’t get me wrong: you should ALWAYS test your data pipelines. But even with testing, there are often critical gaps.
In fact, if you’re in data, dealing with broken pipelines, missing rows, and duplicate data (as well as the complications and frustrations that come with data downtime) is probably a familiar experience, even with testing.
While VP of Operations at Gainsight, my previous company, “Where is my data? Why is the data wrong? Who moved this row?” were all common messages in my team’s Slack channel. At times it felt like the pings never stopped.
Critical tables would fail to update. Mapping lineage between data assets and downstream tables felt like a never-ending corn maze. Freshness anomalies would pop up out of nowhere faster than you could say “data mesh.”
By the time we figured out the root cause of these issues and worked to mitigate it, the damage was already done.
As a result of these incidents and many others, executives flooded my inbox with complaints regarding the quality of our data. They all had one common theme: lack of trust.
Fortunately, new approaches have emerged over the past few years to supplement testing and monitoring alone.
To help folks get started in their journey to data trust, I put together a quick guide explaining why and how to get started with data observability.
What is data observability?
Data observability is an organization’s ability to fully understand the health of the data in their system. It works by applying DevOps Observability best practices to eliminate data downtime. With automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues, data observability leads to healthier data pipelines, more productive data teams, and most importantly happier data consumers.
Like the three pillars of observability in software engineering, data observability can be broken down into its own five pillars:
- Freshness: Freshness seeks to understand how up-to-date your data tables are, as well as the cadence at which your tables are updated. Freshness is particularly important when it comes to decision-making; after all, stale data is basically synonymous with wasted time and money.
- Distribution: Distribution, in other words, a function of your data’s possible values, tells you if your data is within an accepted range. Data distribution gives you insight into whether or not your tables can be trusted based on what can be expected from your data.
- Volume: Volume refers to the completeness of your data tables and offers insights into the health of your data sources. If 200 million rows suddenly turn into 5 million, you should know.
- Schema: Changes in the organization of your data, in other words, schema, often indicate broken data. Monitoring who makes changes to these tables and when is foundational to understanding the health of your data ecosystem.
- Lineage: When data breaks, the first question is always “where?” Data lineage provides the answer by telling you which upstream sources and downstream ingestors were impacted, as well as which teams are generating the data and who is accessing it. Good lineage also collects information about the data (also referred to as metadata) that speaks to governance, business, and technical guidelines associated with specific data tables, serving as a single source of truth for all consumers.
What are the core elements of a data observability platform?
Whether you are building your own data observability solution or evaluating one on the market, here are six things to consider when choosing a data observability solution.
- Time-to-value: Does It connect to your existing stack quickly and seamlessly and not require modifying your pipelines, writing new code, or using a particular programming language? If it is able to connect quickly and seamlessly, you will be able to see the benefits much sooner and maximize your testing coverage without making major investments.
- Security-first architecture: Does It monitor your data at rest and not require extracting the data from where it is currently stored? A solution that can monitor data at rest will scale across your data platform and be cost-effective for your organization. Additionally, it ensures that your organization is compliant with the highest security standards.
- Minimal configuration: Does It require minimal configuration on your end to get up and running and practically no threshold-setting? A great data observability platform uses ML models to automatically learn your environment and your data. It uses anomaly detection techniques to let you know when things break. It minimizes false positives by taking into account not just individual metrics, but a holistic view of your data and the potential impact from any particular issue. As a result, you won’t have to spend valuable engineering resources configuring and maintaining noisy rules. At the same time, it gives you the flexibility to set custom rules for critical pipelines directly in your CI/CD workflow.
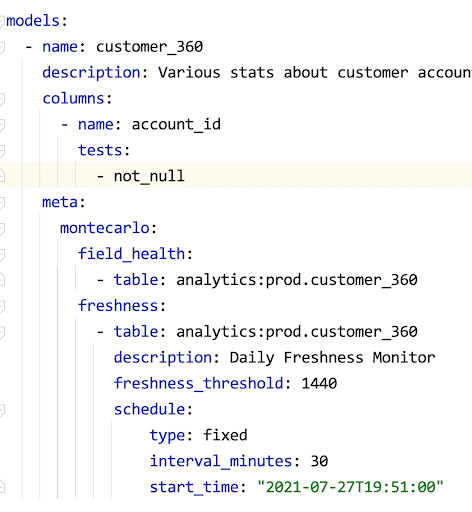
- End-to-end lineage: Does it provide end-to-end lineage to track upstream and downstream dependencies? The solution should require no prior mapping of what datasets need to be monitored and in what way. Being able to understand lineage allows you to identify key resources, key dependencies, and key invariants so that you get broad observability.
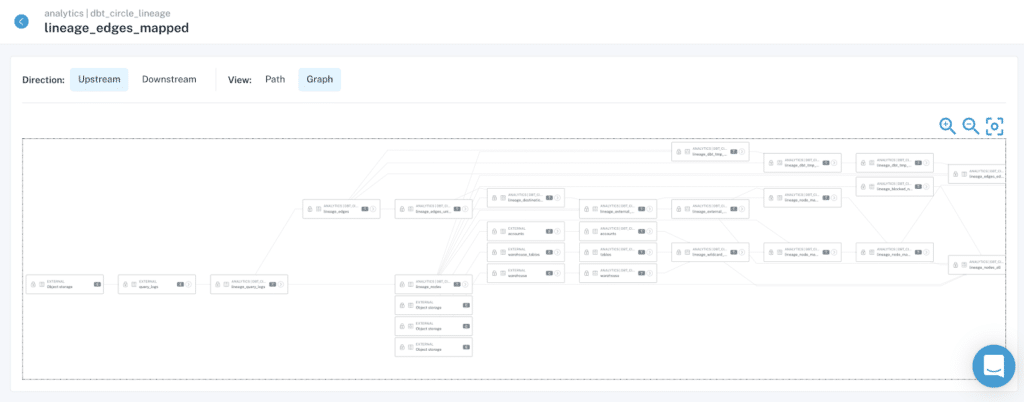
- Communication: Do the alerts generated by the solution provide rich context that enables rapid triage and troubleshooting? The solution you choose should allow you to effectively communicate with stakeholders impacted by data reliability issues. Unlike ad hoc queries or simple SQL wrappers, such monitoring doesn’t stop at “field X in table Y has values lower than Z today.”

- Minimizing time to detection and time to resolution: Does it prevent issues from happening in the first place? Data observability platforms can accomplish this by exposing rich information about data assets across the five pillars so that changes and modifications can be made responsibly and proactively.
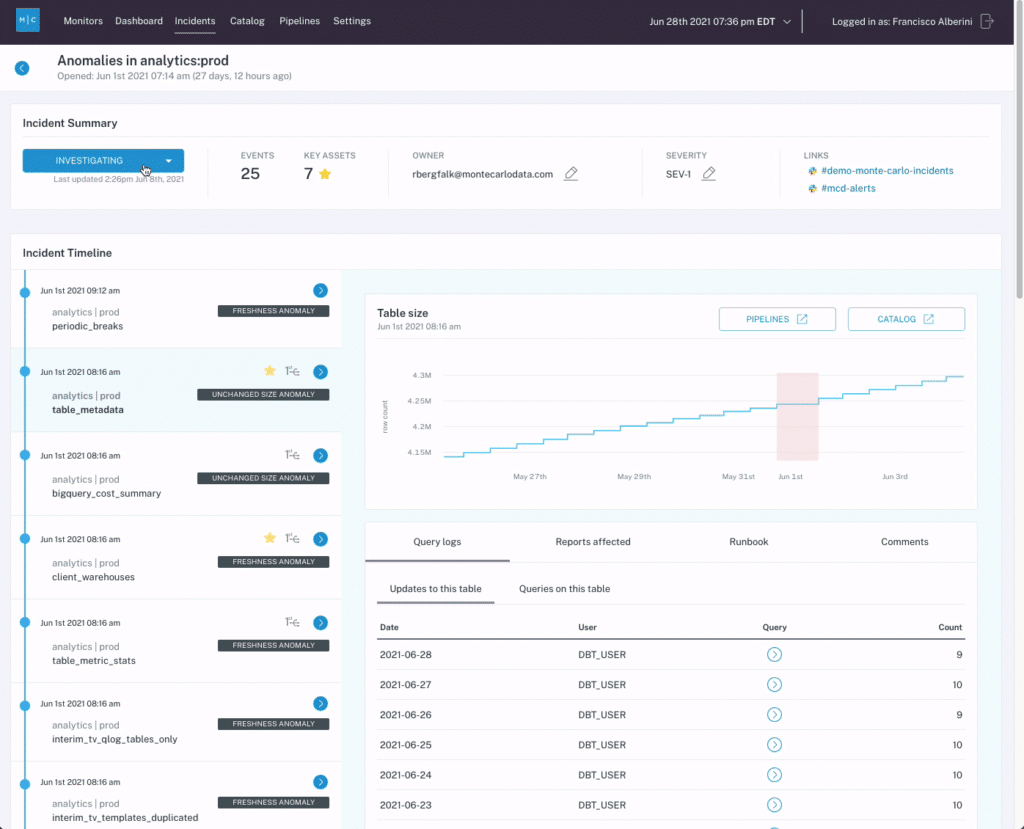
If these 6 requirements are addressed, your data observability strategy is on the right course.
Why you need both testing and observability
Data testing is the process of validating your assumptions about your data at different stages of the pipeline, and it’s a P0 when it comes to implementing good data hygiene. Data testing helps by conducting static tests for null values, uniqueness, referential integrity, and other common indicators of data problems. These tools allow you to set manual thresholds and encode your knowledge of basic assumptions about your data that should hold in every run of your pipelines.
You can even use testing to determine whether or not your data meets your criteria for validity — such as staying within an expected range or having unique values. This is very similar in spirit to the way software engineers use testing to alert on well-understood issues that they anticipate might happen.
But what about testing for data quality issues you don’t know will happen to your data (in other words, unknown unknowns)?
A little change to a line of code causes an API to stop collecting data that powers a popular product. Or an unintended change to ETL leading to tests not being run, allowing bad data to enter your data ecosystem. Both of those examples illustrate how even the best data pipelines can be broken by unknown unknowns.
Similarly, data testing alone is not enough to prevent broken data pipelines, just as unit testing is insufficient to ensure reliable software. In the same way that our software engineering colleagues monitor the health of their applications with tools such as New Relic, DataDog, and AppDynamics, data demands a similar approach. Modern data teams should be leveraging both testing and observability across their pipelines to ensure consistent reliability.
When organizations build data pipelines, speed often takes priority over data reliability. So, teams tend to opt for little or no testing, putting it on the back burner. As a result, data teams are forced to go back and add coverage to existing pipelines when problems arise. This results in teams taking a reactive rather than proactive approach to resolving data quality issues.
An approach of both testing and observability can reduce some of the challenges that come with data testing debt. Data teams have greater visibility into existing pipelines and can proactively tackle data quality issues before they impact downstream sources and stakeholders.
How to build a practice of data trust
To solve data quality problems, data teams are turning to proactive solutions to prevent data quality issues once and for all. While anomaly detection is great for detecting data quality issues, relying on anomaly detection alone doesn’t cut it when it comes to actually understanding root cause, conducting impact analysis, and even resolving the issues at hand.
Data teams need to understand:
- What exactly broke?
- Who is impacted downstream by it?
- Why did it break?
- Where is broken?
- What exactly is the root cause of the issue?
Much in the same way that DevOps applies a continuous feedback loop to improving software, applying data observability beyond anomaly detection allows teams to leverage the same blanket of diligence for data.
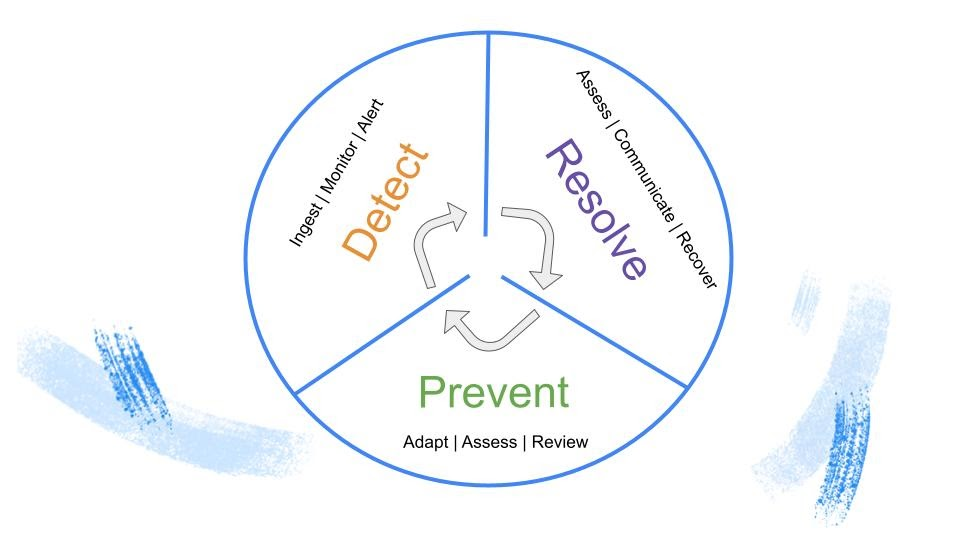
Best-in-class data observability frameworks will allow data teams to:
- Be the first to know about data quality issues in production.
- Fully understand the impact of the issue.
- Fully understand where the data broke.
- Take action to fix the issue.
- Collect learnings so over time you can prevent issues from occurring again.
By applying this approach, data teams can better collaborate to identify, resolve and prevent data quality issues from occurring in the first place, and truly optimize data observability to its full potential.
Moving forward with data observability
As these solutions and approaches evolve, I’m excited to see how the industry continues to adapt best practices (CI/CD, version control, documentation, agile development, etc.) from our friends in software engineering, while continuing to make them specific to the demands of modern data ecosystems.
And just maybe, the next time someone asks you “where did my data go?” you’ll have the answer. If not, at least you’ll be a few steps closer.
Additional Reading
- Data Observability: Five Quick Ways to Improve the Reliability of Your Data
- The Ultimate Data Observability Checklist
- Beyond Monitoring: The Rise of Observability
- 5 Things Every Data Engineer Needs to Know About Data Observability
Interested in learning more? Reach out to Barr and book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.