Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Mesh vs Data Warehouse: 3 Key Differences

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Data mesh vs data warehouse is an interesting framing because it is not necessarily a binary choice depending on what exactly you mean by data warehouse (more on that later).
Both are popular data management frameworks that help teams leverage their data effectively, but they do so in very different ways and with different overarching goals.
Despite their differences, however, both approaches require high-quality, reliable data in order to function. Without a process to observe their data and ascertain its quality, neither the data mesh nor the data warehouse can ever truly take off.
Here are three key differences between data mesh and data warehouse—and the overarching similarity that unites them.
Table of Contents
- What is a Data Warehouse?
- What is a Data Mesh?
- Data Mesh vs Data Warehouse: 3 Key Differences
- The Importance of Data Observability for the Data Warehouse – and Data Mesh
What is a Data Warehouse?
The amount of confusion around a term as fundamental to data engineering as “data warehouse” is remarkable, but understandable. The confusion stems from how the meaning has evolved from when it was first coined by Bill Inmon during the on-premises database days.
Originally, the term “enterprise data warehouse” referred to a specific type of data modeling methodology (you may have heard of Kimball or data vault which are alternative methodologies). All of an organization’s data would be integrated into a single source of truth. Importantly, related data elements are linked so that they are a mirror to the operations in the real world. This consists of entities (New York City), classes (city) with attributes (population: 8.5 million) and events (Giants football game).
Data is extracted, transformed, and loaded in the data warehouse like puzzle pieces to form this picture of reality. Smaller parts of the picture, data marts, can be created from this master picture for a subset of users and use cases (marketing for example).
Classic enterprise data warehouses and data modeling have fallen out of favor in the modern data stack era. This era has been shaped and defined by the rise of cloud based analytical databases such as Snowflake, Redshift, and BigQuery. Today, when a data professional uses the term “data warehouse” they are likely referring to these cloud solutions that feature architectures with separate compute query engine and data storage.
As Mode co-founder Benn Stancil put it:
Snowflake, for instance, has largely moved away from calling itself a database in favor of the data cloud. I get the reasoning; the platform does a lot more than your everyday database. But for Snowflake, I think that’s a missed opportunity. Rather than rebranding themselves, they could’ve rebranded the data warehouse. They could’ve said, as Steve Jobs did, that they reinvented the database. They aren’t a warehouse with lots of extra features; they’re just a warehouse—and for anyone else to be one, they have to have those same features.
In most organizations, their cloud data warehouse will not be a well organized, modeled central source of truth. For example, Snowflake offers data warehouses in different sizes and organizations may have several “data warehouses” to support different data use cases.
It is also common for organizations to have multiple layers to their data infrastructure such as a data warehouse or raw data, a staging data warehouse, and a production data warehouse. A data mesh might leverage one or several cloud data warehouses depending on how closely the organization adheres to the dogma.
What is a Data Mesh?
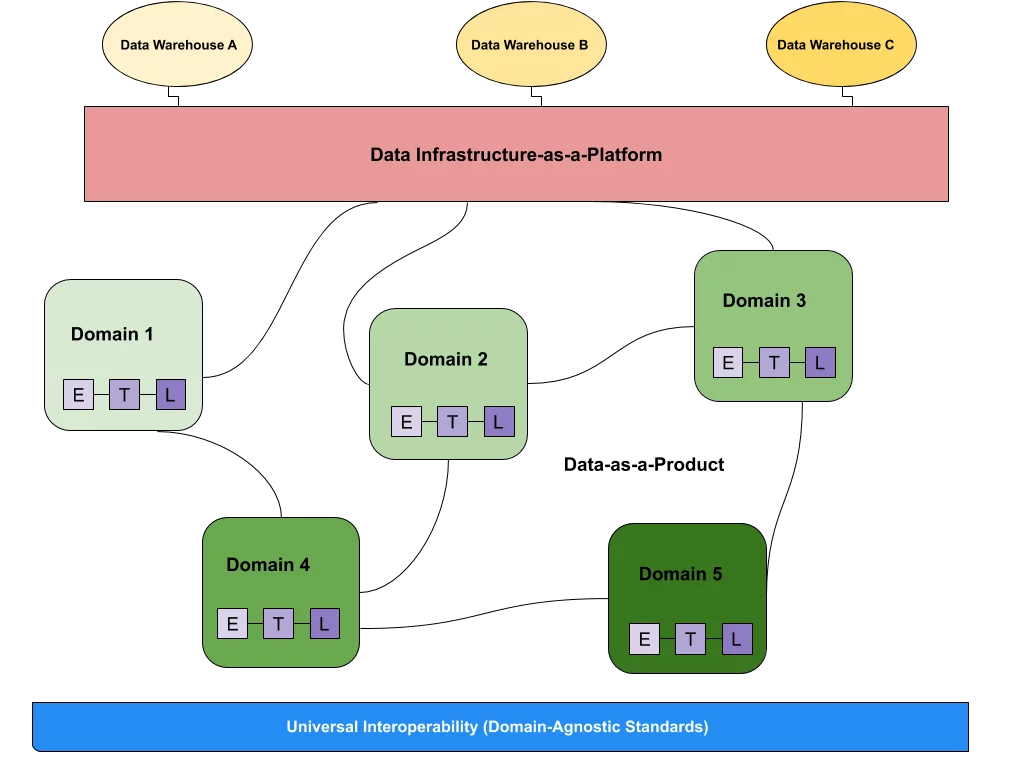
The term “data mesh” has fueled plenty of industry buzz since 2019, when Zhamak Deghani coined the term and data-first companies raced to embrace it. Data mesh is a type of platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design.
Unlike data warehouses and data lakes, the data mesh decentralizes data ownership. Companies that adopt data mesh architecture view data as a product, and this view empowers domain teams (typically a business department like marketing) to own their own data pipelines. These domains are ultimately connected by a universal interoperability layer that standardizes rules and syntax across the organization.
Each data mesh adheres to the following principles:
- It supports a domain-oriented architecture, with distributed data ownership across domain-specific teams
- It views data as a product and assigns accountability to each domain-oriented team
- It empowers teams with a self-serve data infrastructure
- It maintains order and consistency with federated data governance
A data mesh architecture can be an excellent selection for companies seeking to enhance the flexibility and scalability of their data. Reducing the associated pressure on centralized data teams removes organizational bottlenecks and helps teams utilize data in more agile ways.
Data Mesh vs Data Warehouse: 3 Key Differences
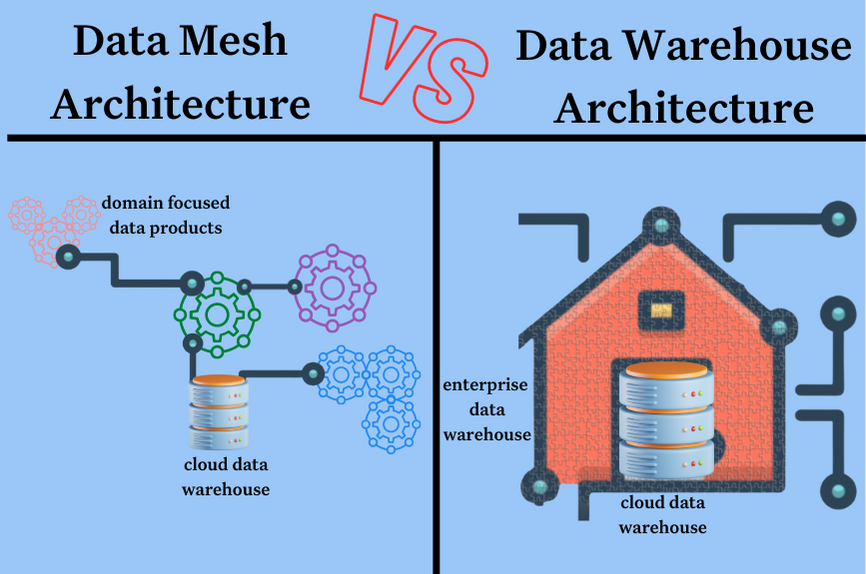
Data mesh and enterprise data warehouse methodologies both address different approaches to managing data, and they have multiple differences in terms of data ownership, data governance, data processing, and data delivery.
In a data mesh approach, multiple domain-oriented teams own their respective data, which distributes ownership across the organization. Data teams that implement an enterprise data warehouse approach to data management often retain ownership of the organization’s data within a central location.
Teams that utilize an enterprise data warehouse model maintain data governance with a central data team, and companies leveraging data mesh employ federated data governance across multiple distributed teams.
Beyond these details, there are three key structural and strategic differences for data mesh vs data warehouse.

Source of truth
The main purpose of an enterprise data warehouse according to Bill Inmon is to provide a central source of truth. A data mesh, on the other hand, isn’t designed to have a central source of truth. Instead, each data product is designed for a purpose and specific business use case. While data mesh does account for a universal operability layer, the methodology is not concerned with having data products cohere into a larger picture or source of truth.
Central vs decentralized
Ultimately, the goals of a data mesh differ from the goals of a data warehouse. Often, teams implement data mesh to democratize data access, empower various domains, and scale fast and flexibly while looking forward. Treating data as a product and enabling a self-service approach to data management are data mesh qualities that work in service of this goal.
A data warehouse, however, centralizes data management. This has a higher upfront cost and less agility, but it can allow for greater insights, easier cross domain exploration, and more sophisticated analysis.
Redundancies and business alignment
The enterprise data warehouse was built in an era where storage was costly. Data modeling required expertise and considerable engineering hours, but ultimately made the organization more efficient in the long run by ensuring there was no duplicate data.
Not only is it likely that there will be some duplicate data contained within a data mesh architecture, there may even be duplicate technologies, infrastructures, and services! The data mesh architecture was developed in an era when compute and storage are relatively cheap, and the biggest cost to organizations are the opportunity costs from bottlenecks and slow central processes. Data mesh deliberately makes the trade of redundancy in exchange for speed and having data teams embedded and more closely aligned within the business.
The Importance of Data Observability for the Data Warehouse – and Data Mesh
Regardless of the approach organizations take to data management and architecture, one thing is certain: neither a data warehouse nor a data mesh can operate as effectively as possible without high-quality, reliable data.
As noted in this Martin Fowler post, ensuring data quality is a challenge for data warehouses. “Trying to get an authoritative single source for data requires lots of analysis of how the data is acquired and used by different systems…On top of this, data quality is often a subjective issue, different analysis has different tolerances for data quality issues, or even a different notion of what is good quality.”
Similarly, organizations empowering various domain-oriented teams to take charge of their data first need to ensure that data’s reliability. If data pipelines are outdated, slow, or constantly breaking, these distributed teams will just be frustrated—and the data mesh initiative will be less likely to succeed.
Whether they’re using a data warehouse or data mesh, organizations need to embrace data observability. Data observability is an organization’s ability to fully understand the health of the data in their systems. Data observability eliminates data downtime by applying best practices learned from DevOps to data pipeline observability.
Data observability is crucial for any type of modern data architecture, particularly as organizations use increasing volumes of data coming from increasingly varied sources. Data observability tools like Monte Carlo can help businesses ensure data quality and reliability in both a data mesh and a data warehouse environment. This assurance can, in turn, increase the ROI of the organization’s data.
Reach out today to learn more about how Monte Carlo’s data observability platform can enhance your data warehouse or data mesh and try its features for yourself.
Our promise: we will show you the product.
Read more posts.