Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Building Spark Lineage For Data Lakes

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.

Corey Fritz
Senior Software Engineer at Monte Carlo.
When a data pipeline breaks, data engineers need to immediately understand where the rupture occurred and what has been impacted. Data downtime is costly.
Without data lineage–a map of how assets are connected and data moves across its lifecycle–data engineers might as well conduct their incident triage and root cause analysis blindfolded. There are two types of data lineage: table-level lineage and column-level lineage (also known as field-level lineage). In Spark, data lineage is built using the RDD (Resilient Distributed Dataset) abstraction, which keeps track of all transformations applied to it.

Monte Carlo’s data observability platform does an excellent job mapping table lineage (even field level lineage!) for SQL based transformations, but some of the most popular, Spark-based systems remained a blindspot for us and for the industry at large.
Because one of our core principles is to provide end-to-end coverage in a unified platform, we set off to engineer a solution to this challenge and integrate Spark into our lineage feature.
We knew it wouldn’t be easy, but beating the odds is indelible to our engineering culture.
Table of Contents
How we automate SQL lineage
Developing data lineage for SQL is a much different process than developing Spark lineage.
To retrieve data using SQL, a user would write and execute a query, which is then typically stored in a log. These SQL queries contain all the breadcrumbs necessary to trace which columns or fields from specific tables are feeding other tables downstream.
For example, we can look at this SQL query which will display the outcomes of at-bats for a baseball team’s players…
SELECT player.first_name, player.last_name, bat.date, bat_outcome.outcome_text
FROM player
INNER JOIN bat ON bat.player_id = player.id
INNER JOIN bat_outcome ON bat.bat_outcome_id = bat_outcome.id

… and we can understand the connections between the above player, bat, and bat_outcome tables.
You can see the downstream field-to-field relationships in the resulting “at-bat outcome” table from the SELECT statements and the table-to-field dependencies in the non-SELECT statements.
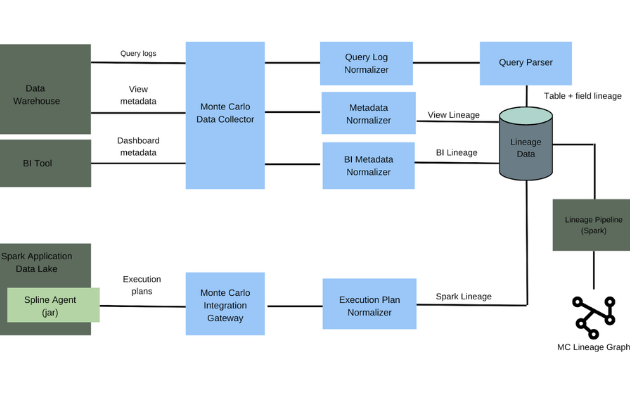
Metadata from the data warehouse/lake and from the BI tool of record can then be used to map the dependencies between the tables and dashboards.
Parsing all this manually to develop end-to-end lineage is possible, but it’s tedious.
It also becomes outdated virtually the moment it’s mapped as your environment continues to ingest more data and you continue to layer on additional solutions. So Monte Carlo automates it.
We use a homegrown data collector to grab our customers’ SQL logs from their data warehouse or lake, stream the data to different components of our data pipelines. We leverage the open source ANTLR parser, which we heavily customized for various dialects of SQL, in a Java-based lambda function to comb through the query logs and generate lineage data.
The back-end architecture of our field-level SQL lineage solution looks something like this:
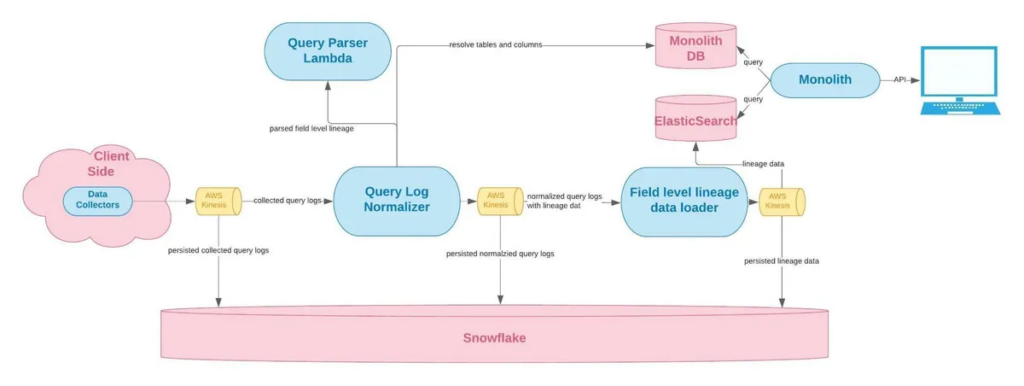
Easy? No. Easy compared to Spark lineage? Absolutely.
How we solved end-to-end Spark lineage
Apache Spark doesn’t quite work the same way. Spark supports several different programming interfaces that can create jobs such as Scala, Python, or R.
Regardless of the programming interface that’s used, it gets interpreted and compiled into Spark commands. Behind the scenes, there is no such thing as a concise query, or a log of those queries.
Following are examples from Databricks notebooks in Python, Scala, and R that all do the same thing – load a CSV file into a Spark DataFrame.
Python
%python
data = spark.read.format('csv') \
.option('header', 'true') \
.option('inferSchema', 'true') \
.load('/data/input.csv')Scala
%scala
val data = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/cfritz/input.csv")R
%r
data <- read.df("/data/input.csv",
source = "csv",
header="true",
inferSchema = "true")After Spark interprets the programmatic code and compiles the commands, it creates an execution graph (a DAG or Directed Acyclic Graph) of all the sequential steps to read data from the source(s), perform a series of transformations, and write it to an output location.
That makes the DAG the equivalent of a SQL execution plan. Integrating with it is the holy grail of Spark lineage because it contains all the information needed for how data moves through the data lake and how everything is connected.
Spark has an internal framework called QueryExecutionListeners which you can configure in Spark to listen for events where a command gets executed and then pass that command to the listener.
For example, below is the source code for the listener implementation used by an open-sourced listening agent.
package za.co.absa.spline.harvester.listener
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.execution.QueryExecutionimport org.apache.spark.sql.util.QueryExecutionListenerimport za.co.absa.spline.harvester.SparkLineageInitializer
class SplineQueryExecutionListener extends QueryExecutionListener {
private val maybeListener: Option[QueryExecutionListener] = {
val sparkSession = SparkSession.getActiveSession
.orElse(SparkSession.getDefaultSession)
.getOrElse(throw new IllegalStateException("Session is unexpectedly missing. Spline cannot be initialized."))
new SparkLineageInitializer(sparkSession).createListener(isCodelessInit = true)
}
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
maybeListener.foreach(_.onSuccess(funcName, qe, durationNs))
}
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {
maybeListener.foreach(_.onFailure(funcName, qe, exception))
}
}Instead of building a series of listeners from scratch, we decided to take advantage of that open source technology, Spline.
Smart developers had already invested several years into building a Spark agent to listen for these events, capture the lineage metadata, and transform it into graph format which we could then receive via a REST API (other options for receiving this data are available as well).
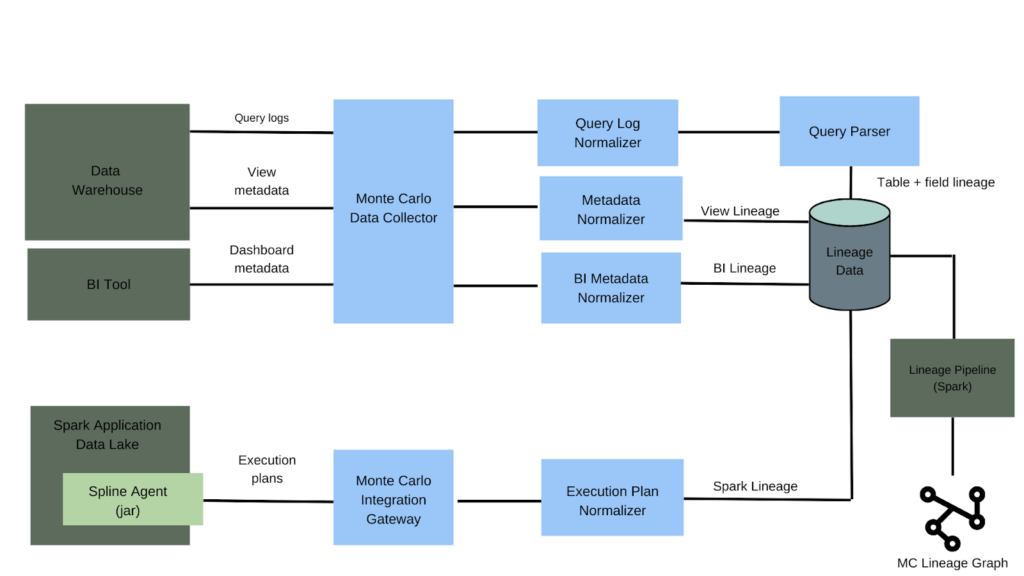
Once we have that representation of the execution plan we send it to the Integration Gateway and then a normalizer which converts it into Monte Carlo’s internal representation of a lineage event.
From there, it’s integrated with other sources of lineage and metadata to provide a single end-to-end view for each customer.
It’s a really elegant solution….here’s why it doesn’t work.
The challenges of Spark lineage
What makes Spark difficult from a lineage perspective, is what makes it great as a framework for processing large amounts of unstructured data. Namely, how extensible it is. Spark also provides fault tolerance by maintaining the lineage of data transformations. In case of a failure, Spark can recompute the lost partition of an Resilient Distributed Dataset (RDD) abstraction by following the lineage. The lineage graph in Spark is stored on the driver where the RDDs live.
You can run Spark jobs across solutions like AWS Glue, EMR, and Databricks. In fact, there are multiple ways you can run Spark jobs in Databricks alone.
You can also break lineage in Spark by if the DAG is too big, or the number of stages and tasks is too large. You can break Spark lineage through a Checkpoint, LocalCheckpoint, or a ReCreate Frame/Dataset.
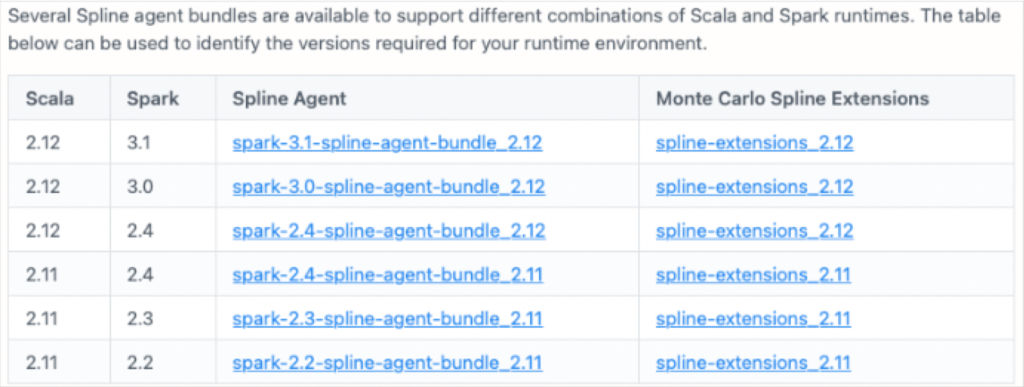
Configuring our Spark lineage solution– specifically how you add JAR files to Spark’s runtime classpath–would vary depending on how and where our customers ran their Spark jobs across these solutions and what combinations of Scala and Spark versions those solutions leveraged.
At Monte Carlo, we strongly emphasize ease-of-use and time-to-value. When you find yourself inserting a table like this into the draft documentation, it may be a sign to re-evaluate the solution.
The second challenge is that, like SQL statements, the vocabulary of Spark commands is ever expanding. But, since it is a newer framework than SQL, it’s growing at a slightly faster rate.
Every time a new command is introduced, code has to be written to extract the lineage metadata from that command. As a result, there were gaps in Spline’s parsing capabilities with commands that weren’t yet supported.
Unfortunately, many of these gaps needed to be filled for our customers’ use cases. For example, a large biotech company needed coverage for when it utilized the Spark MERGE command which, just like the SQL statement and tables, combines two dataframes together by inserting what’s new from the incoming dataframe and updates any existing records it finds.
For example, taking our simplistic baseball tables from before, this is how the new Spark MERGE command could be used to add new at-bats, update previously existing at-bats with corrected data, or maybe even delete at-bats that are so old we don’t care about them any more.
MERGE into bat
using bat_stage
on bat.player_id = bat_stage.player_id
and bat.opponent_id = bat_stage.opponent_id
and bat.date = bat_stage.date
and bat.at_bat_number = bat_stage.at_bat_number
when matched then
update set
bat.bat_outcome_id = bat_stage.bat_outcome_id
when not matched then
insert (
player_id,
opponent_id,
date,
at_bat_number,
bat_outcome_id
) values (
bat_stage.player_id,
bat_stage.opponent_id,
bat_stage.date,
bat_stage.at_bat_number,
bat_stage.bat_outcome_id
)It’s a relatively new command and Spline doesn’t support it. Additionally, Databricks has developed their own implementation of the MERGE statement into which there is no public visibility.
These are big challenges sure, but they also have solutions.
We could ensure there is more client hand holding for Spark lineage configuration. We could hire and deploy an army of Scala ninjas to contribute support for new commands back to the Spline agent. We could even get cheeky and reverse engineer how to derive lineage from Databricks’ MERGE command implementation.
A good engineer can build solutions for hard problems. A great engineer takes a step back and asks, “Is the juice worth the squeeze? Is there a better way this can be done?”
Oftentimes buying or integrating with off-the-shelf solutions is not only more time efficient, but it prevents your team from accruing technical debt. So we went in another direction.
Partnering with Databricks
During the beta-testing of our Spark lineage solution, we found the primary use case for virtually every customer was for lineage within Databricks.
We are great partners with Databricks and were pleased to announce a robust automated monitoring and alerting integration supporting the platform last year.
We determined the best path forward was to work closely with the team to develop our lineage solution and we are excited to deepen this relationship to ensure our mutual customers achieve end-to-end data observability.
To that end, we are announcing we are fully integrated with Databricks data lineage via the Unity Catalog. The Unity Catalog is now available in preview and is a unified governance solution for all data and AI assets in the data lakehouse. Some of the features in Databrick’s lineage solution include:
- Automated run-time lineage: Unity Catalog automatically captures lineage generated by operations executed in Databricks. This helps data teams save significant time compared to manually tagging the data to create a lineage graph.
- Support for all workloads: Lineage is not limited to just SQL. It works across all workloads in any language supported by Databricks – Python, SQL, R, and Scala. This empowers all personas — data analysts, data scientists, ML experts — to augment their tools with data intelligence and context surrounding the data, resulting in better insights.
- Lineage at column level granularity: The Unity Catalog captures data lineage for tables, views, and columns. This information is displayed in real-time, enabling data teams to have a granular view of how data flows both upstream and downstream from a particular table or column in the lakehouse with just a few clicks.
- Lineage for notebooks, workflows, and dashboards: Unity Catalog can also capture lineage associated with non-data entities, such as notebooks, workflows, and dashboards. This helps with end-to-end visibility into how data is used in your organization. As a result, you can answer key questions like, “if I deprecate this column, who is impacted?”
- Built-in security: Lineage graphs in Unity Catalog are privilege-aware and share the same permission model as Unity Catalog. If users do not have access to a table, they will not be able to explore the lineage associated with the table, adding an additional layer of security for privacy considerations.
- Easily exportable via REST API: Lineage can be visualized in the Data Explorer in near real-time, and retrieved via REST API to support integrations with our catalog partners.
We are thrilled to be partnering with Databricks on this solution and we hope our experience has helped shed some light both on the intricacies of automated and Spark lineage.
Would end-to-end and Spark lineage help your team’s data initiatives? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.