 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How To Create Data Trust Within Your Organization

Shane Murray
Shane is Field CTO of Monte Carlo. Previously, he served as the SVP of Data & Insights at The New York Times.
Many years ago, an exec approached me after a contentious meeting and asked, “Shane, so is the data trustworthy?”
Perhaps you can relate.
My response at the time probably did not build trust: “Some of it, if not precise, is at least directionally useful.”
What is data trust?
Data trust is the degree to which your data consumers feel comfortable making decisions or automating processes with data. It is often measured with a survey using a net promoter score (NPS) framework. It is impacted based on the dimensions of data quality as well as the reliability, accessibility, and overall usefulness of your data.
I’ve been pondering this question and my unsatisfying response recently as I talk to data leaders about what data quality metric they should use to communicate data reliability, whether that be to executives or to the end-users of their data products such as data analysts.
Data trust is everything. Data trust benefits include increased adoption, faster decision making, and an overall elevation of the data team’s role in key initiatives.
Unfortunately, data trust is also often a lagging indicator of data governance, quality, and reliability. Trust is often assumed until it’s lost, usually following a major incident.
In most cases, data quality was likely objectively in decline behind the curtains far before that data incident occurred. Conversely, major improvements in data quality may also go unnoticed, and data trust will be rebuilt slowly following such an incident.
The relationship between reliability, data trust, and incidents may look something like this:
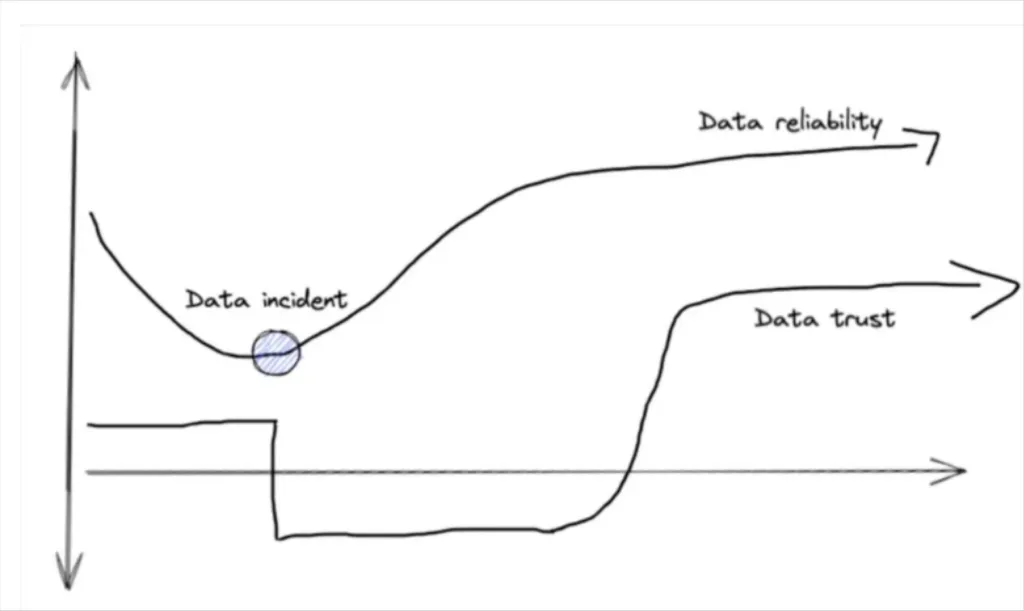
When a data exec recently told me that he roughly measures data trust and quality by “days since the last major incident” it struck a chord. Data incidents are the events that undermine trust, not just in your data but in your entire strategy, product, or team.
So what’s needed then is not a reactive baseline, but a proactive data quality metric. Just like mechanical engineers look for signs their machines need preventive maintenance to avoid costly breakdowns, data engineers need to monitor indicators of data reliability to understand when proactive steps are needed to avoid costly data incidents.
You don’t want to be in a situation where you are repairing the pipeline after its burst and the damage is done. And damage can be done. For example, Unity, the popular gaming software company, cited “bad data” for a $110M impact on their ads business.

But if data trust is the important lagging indicator, then what is the best proactive metric?
The reliability requirements for a specific data product are subject to the type of the data, how it’s used and who uses it. Some data must be highly available (low latency) but accuracy is less critical, such as the data for content or product recommendations. Other data can be delayed without the loss of data trust, but must be deadly accurate when delivered, such as financial or health data.
This is why understanding the business objective and talking to stakeholders when building your data product SLAs is so important.
For simplicity’s sake, let’s segment our data products into three classes in order to address the different expectations for reliability:

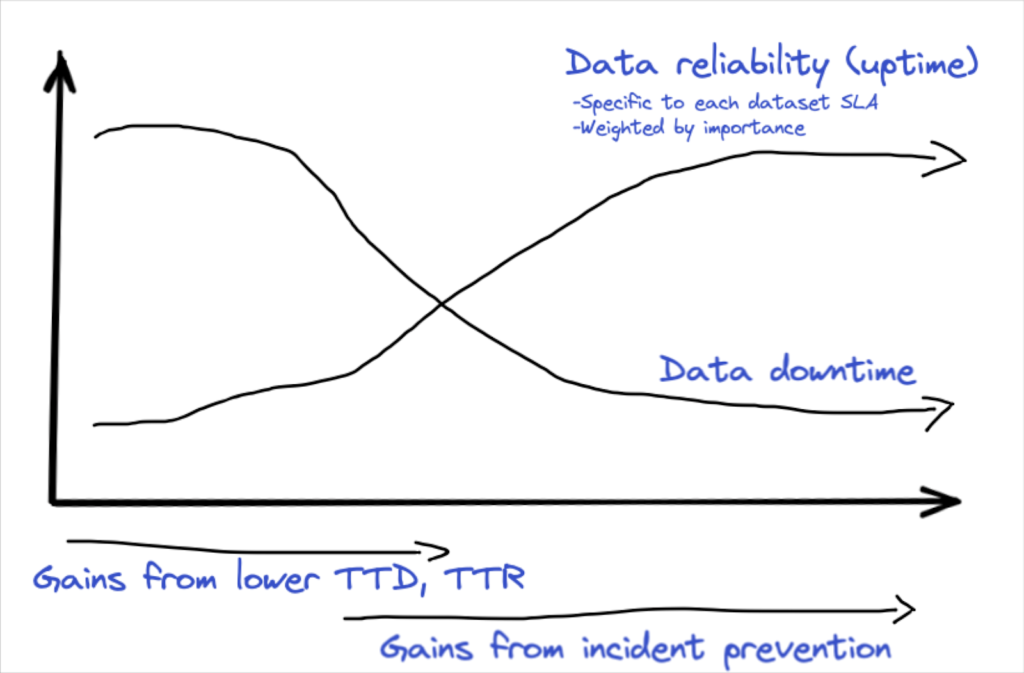
Data downtime, the number of incidents x the time to detection + the time to resolution, is a helpful metric for overall data quality.
“Data uptime” SLAs drill down to another level of detail by indicating the health of our data, based on the specific reliability goals we care about (freshness, accuracy, etc), for the specific data products that are most consequential to our business. That’s what makes it such a helpful, proactive data quality metric.
Then, we might set the following SLAs*:

This data quality metric is:
- Explainable (“data uptime, got it!”),
- Trendable (“data uptime increased 5% this quarter”) and
- Comparable with context (“dataset A with 95% uptime is more reliable than dataset B with 88% uptime,” and both have the same SLAs).
Typically, early gains in uptime (or reductions in downtime) will come from the effectiveness of responding to incidents, reducing the time to detect and resolve. After these improvements, data teams will advance towards targeting the systematic weaknesses that cause incidents, driving further gains in uptime.
*some teams may decide to get even more granular with separate metrics for availability and accuracy depending on the data product.
Focusing on what matters most
The complexity of data warehouses – many domains, thousands of tables – will invariably require a simple distillation of data uptime metrics.
All data incidents are not created equal, some are more severe than others and this severity will impact the loss of data trust resulting from an incident. But incident severity is another lagging indicator, so what would be the best way to account for it within the leading data quality metric, data uptime?
Assigning an importance weight to each table based on its usage and criticality to the business can give you a weighted uptime % for each data domain.
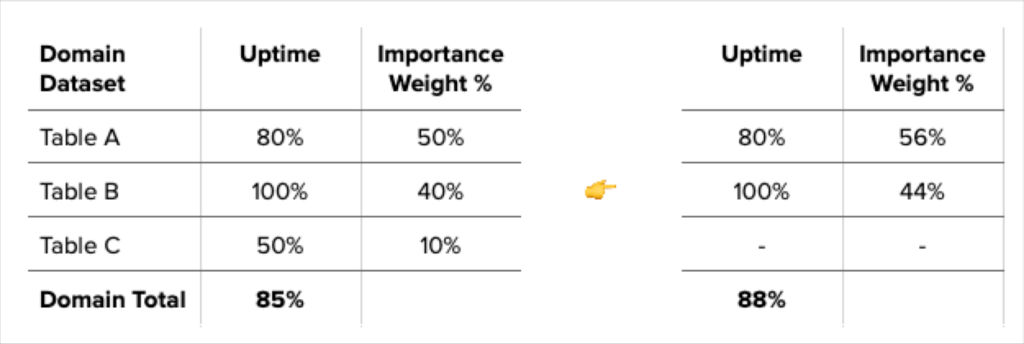
This leads us to another potential path to downtime optimization – cleaning up tables of “low importance” in the warehouse that are contributing to downtime, thereby driving up your overall uptime.
With detailed SLAs we can understand our data reliability levels and fix issues BEFORE they turn into the data incidents that compromise data trust. If nothing else, when it’s your turn to have an executive ask you, “how trustworthy is the data,” you can provide an appropriately data-driven response.
– Shane
Trying to figure out how to build up data trust in your organization? Curious about what data quality metric can be most helpful? Talk to us by filling out the form below.
Our promise: we will show you the product.
Read more posts.





