Product demo.
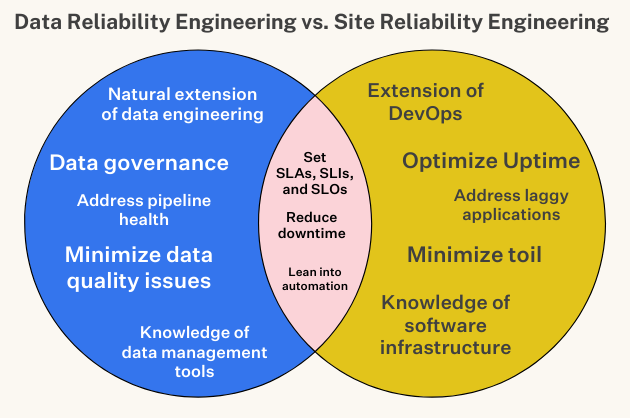
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Quality Solutions: Build or Buy? 4 Things To Know


Stephen Guerguy
Stephen is on Monte Carlos Growth team.

Scott O'Leary
Scott O'Leary is a founding member of Monte Carlo's Sales team.
As data pipelines become increasingly complex, investing in a data quality solution is becoming an increasingly important priority for modern data teams. But should you build it—or buy it?
There are 4 key challenges, opportunities, and trade-offs when considering building or buying a data observability or data quality solution. In this post we will cover:
- The importance of data quality
- Understanding the expected time-to-value for your data quality solution
- Factoring in the opportunity cost of building a data quality solution
- Taking a proactive approach to solving data quality problems
- Scoping data quality solutions
The importance of data quality
As companies ingest more and more data and data ecosystems become increasingly complex—from storing unstructured data in data lakes to democratizing access to a greater number of internal consumers—the onus on data quality has never been higher.
After all, it doesn’t matter how advanced your data platform is or how many dashboards you produce if you can’t rely on the data feeding them.
Ensuring your data is fresh, accurate, and reliable is crucial, but it’s not easy. Data engineers and analysts spend upwards of 40 percent or more of their time tackling data quality issues, distracting them from working on projects that will actually move the needle for the business.
It’s not uncommon for data teams to build their own data quality solutions in-house, layering robust data testing, monitoring for production pipelines, and setting SLAs to track data reliability and manage stakeholder expectations. And for those just getting started? Inspiration is out there, primarily in the form of articles written by Uber, Airbnb, Spotify, Netflix, and other tech giants about their own data quality journeys.
As is the case with any emerging technology, a philosophical (and financial) question quickly follows: should you build or buy a data quality solution?
After talking to hundreds of companies over the last year, we learned that most organizations’ data stacks combine a mix of custom-built, SaaS, and open source solutions. And during these conversations, Heads of Data, Chief Data Officers, and product managers have shared with me the mistakes they have made when choosing between building and buying core elements of their stack.
According to the experts, here are the 4 things you must do when choosing between building or buying your data quality solution:
Understanding the expected time-to-value for your data quality solution
Like any in-house solution, designing, building, scaling, and maintaining an internal data quality solution will take time, money, and headcount. For your Ubers, Airbnbs, and Netflixes of the world, this is no problem. If you have an extensive data engineering and data science team with a significant amount of extra time on their hands, then building could make sense—but at most companies, lack of work for data teams is rarely an issue.
If, like most companies, you don’t have 5+ data engineers and 1 product manager working tirelessly on this problem for the foreseeable future, then you may consider looking beyond in-house solutions to meet your data quality needs.
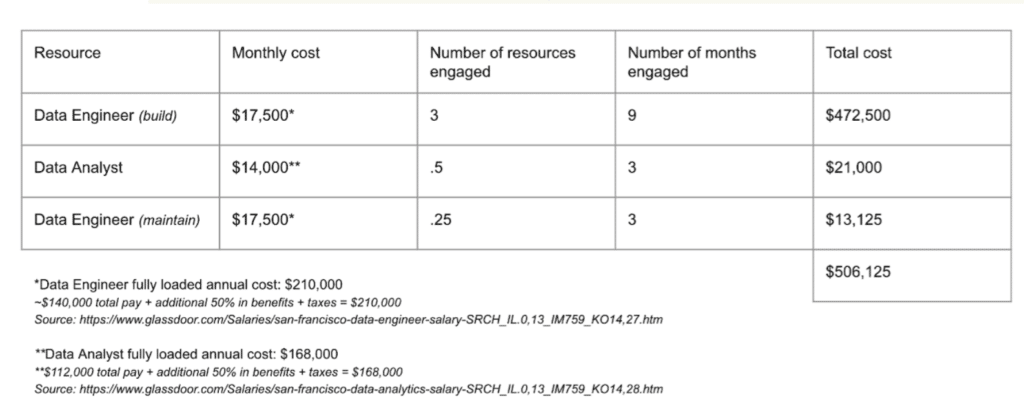
When the data team at a leading insurtech provider investigated building a data observability solution, they realized it would take 30 percent of their data engineering team to build a comprehensive anomaly detection algorithm, a solution that would cost upwards of $450,000/year to build and maintain. They chose to buy instead.
Similarly, a VP of Data Engineering at a healthcare startup we spoke with noted that if he was in his 20s, he would have wanted to build a data quality solution. But now, in his late 30s, he would almost exclusively buy.
“I get the enthusiasm,” he says, “But I’ll be darned if I have the time, energy, and resources to build a data platform from scratch. I’m older and wiser now — I know better than to NOT trust the experts.”

Bottom line, don’t underestimate the time to value when it comes to building data observability or data quality solutions from scratch. In most cases, data engineering time is far too valuable to be spent building a data quality solution that could take you upwards of 1+ year to be up and running. And when it comes to data quality and reliability, most organizations don’t have the time, resources, or reputation to sacrifice.
Factoring in the opportunity cost of building a data quality solution
When your data engineers are spending their time manually building data tests to account for any and all possible edge cases, those are hours that could have been spent solving customer problems, improving your product, or driving innovation.
When you consider that even the most robust testing in the world won’t account for about 80 percent of data issues, it pays to consider the opportunity cost of what it means to be building and maintaining these tests instead of working on projects that will actually move the needle for your business.
Beyond the immediate opportunity costs, data engineers working with a half-measure data quality solution may also spend more time resolving issues when problems do arise, further depleting their energy from these critical endeavors. In fact, we found that data engineers spend about 40 percent of their time manually firefighting data issues; if time is money, that’s no chump change.
When it comes to where you could be spending both time and money- it often makes sense to buy a tried and true data quality solution supported by a dedicated team to help your data engineers troubleshoot any downtime that arises.
For example, after direct-to-consumer mattress brand Resident implemented data quality through Monte Carlo, they saw a 90% reduction in data issues and shortened time-to-detection for the remaining 10%.
As their Head of Data Engineering Daniel Rimon told us, “Before Monte Carlo, I was always on the watch and scared that I was missing something. I can’t imagine working without it now…I think every data engineer has to have this level of monitoring in order to do this work in an efficient and good way.”
Taking a proactive approach to solving data quality problems
Data is bound to break at one point or another, which leads teams to take a reactive approach to fixing errors, instead of being more diligent and proactive about them. And as data pipelines become increasingly complex, reactive approaches to solving data quality issues are not enough.
Testing (one important proactive approach) can help validate your assumptions about your data. You can set manual thresholds, test for null values and other common indicators of data problems, and even use testing to determine if data falls outside an expected range.
Still, while testing can detect and prevent many issues, it is unlikely that a data engineer will be able to anticipate all eventualities during development, and even if they could, it would require an extraordinary amount of time and energy. Data teams that rely on testing may catch problems you can easily predict but will miss out on “unknown unknowns”—issues like distribution anomalies, schema changes, or incomplete or stale data.
Which is why in order to truly take a proactive approach to solve data quality problems the best data teams are leveraging a dual approach, blending data testing with constant monitoring, observability, and other data quality solutions across their entire pipeline.
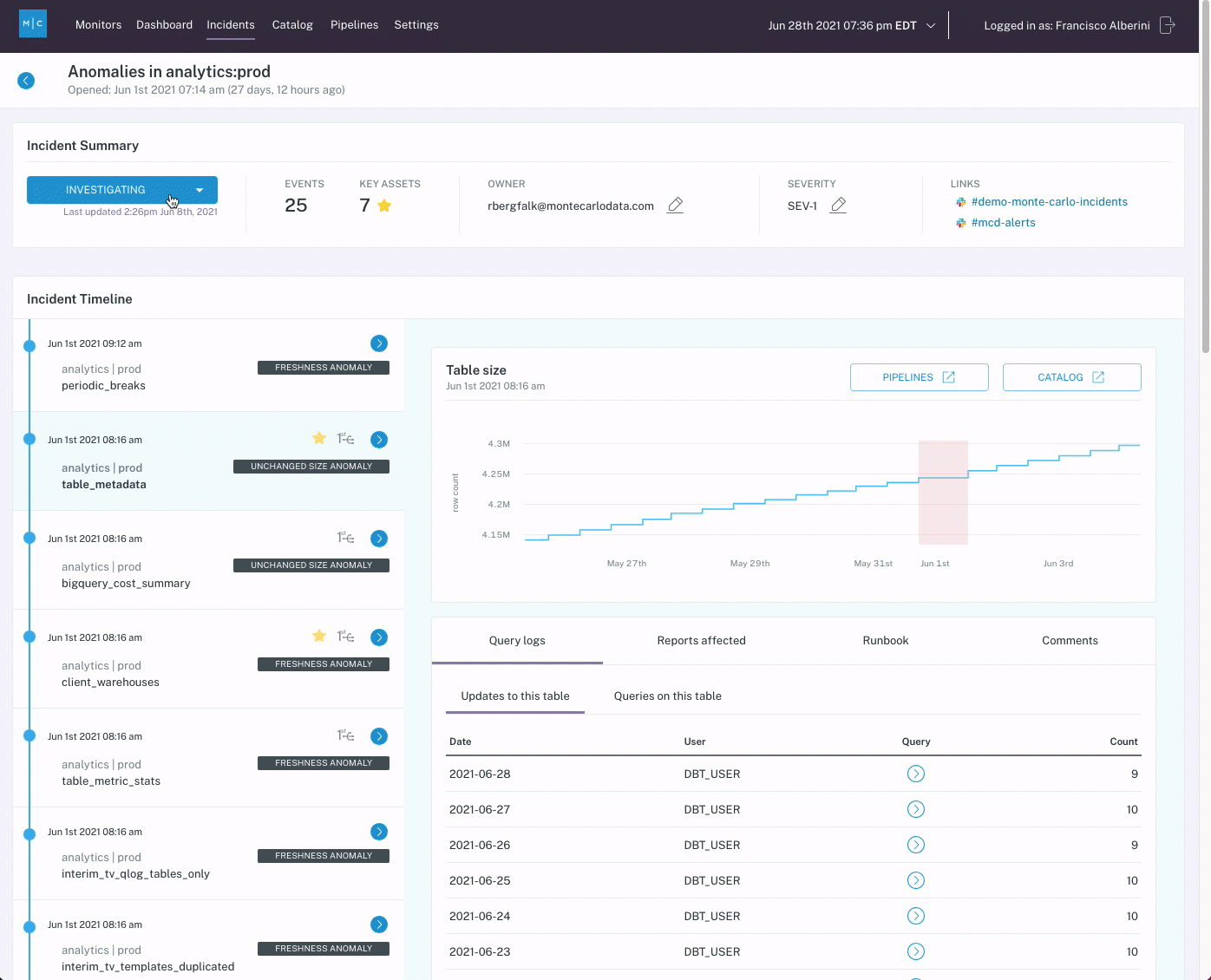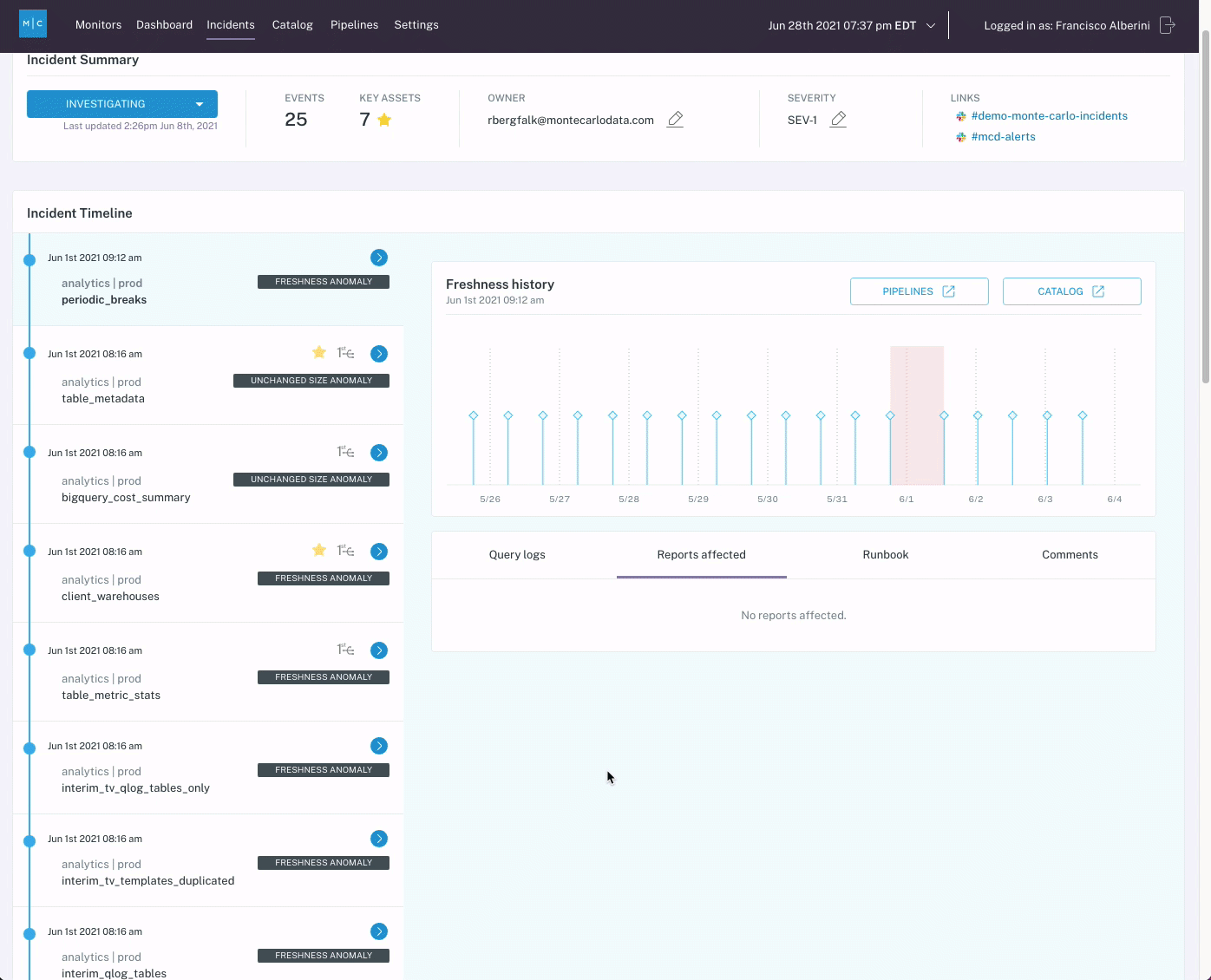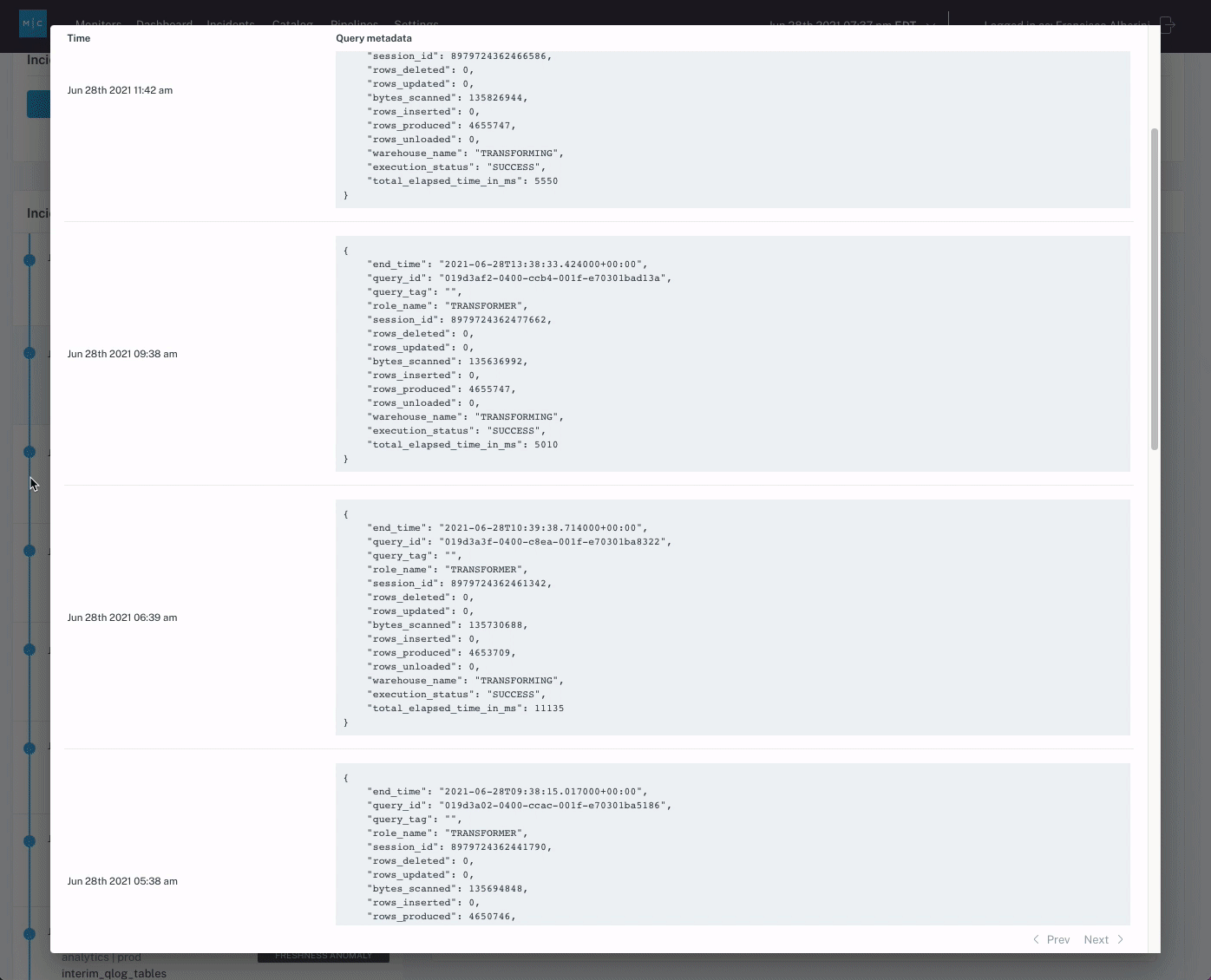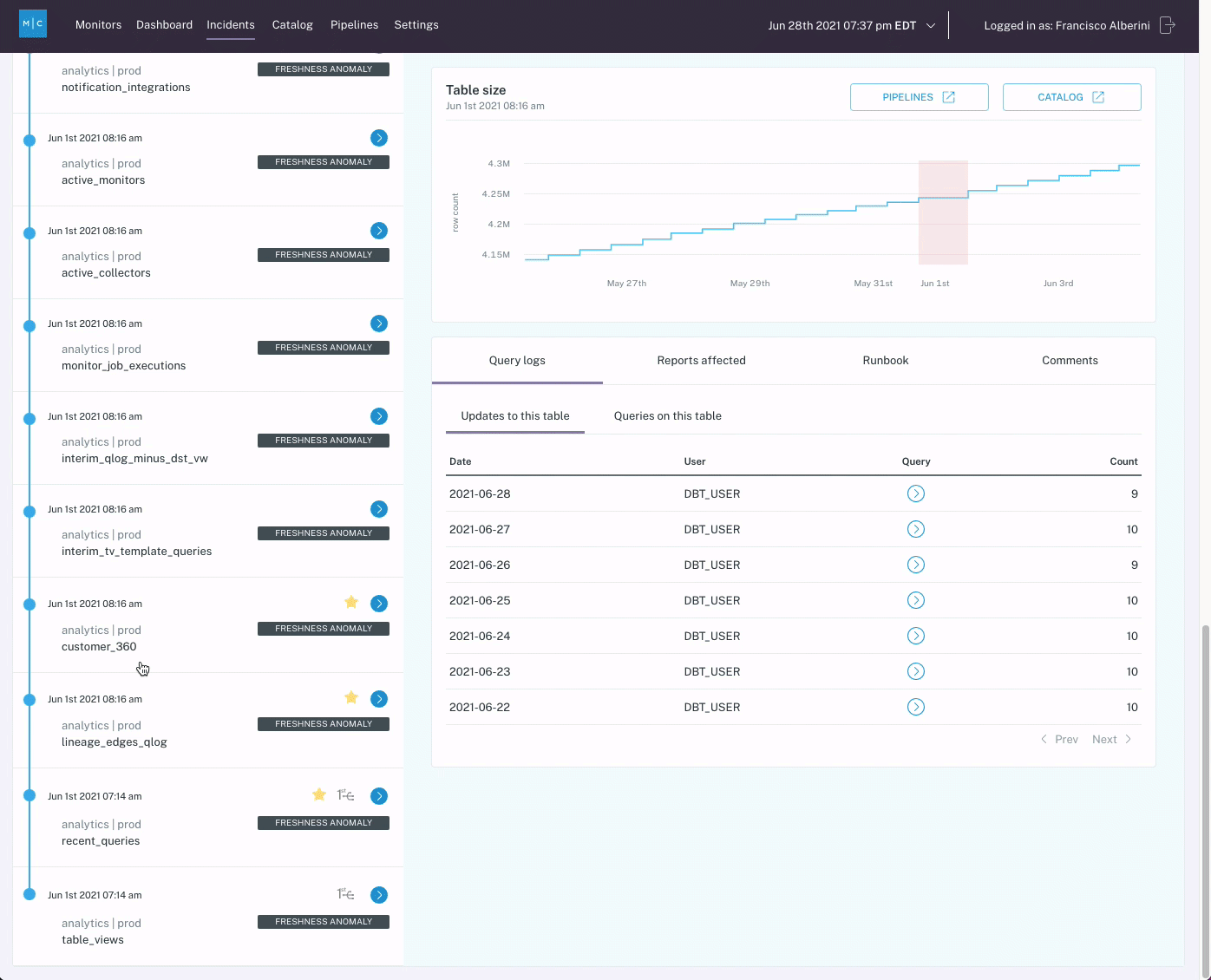
When logistics company Optoro needed to solve the problem of customers being the first to notice and flag data issues, they considered building a homegrown data quality solution to get between their customers and bad data. While their options included developing a custom SQL integrity checker or building source and destination checks, their data team ultimately determined that it would be too time-consuming and the coverage would be too limited for Optoro’s many pipelines.
Ultimately, Optoro chose to buy Monte Carlo instead, and the data team found that the end-to-end automated lineage, which required no manual mapping on their end, was a crucial addition to their data platform and led to an improvement in data quality.
Scoping data quality solutions
Before building or buying any data quality solution, you should understand exactly what you are looking to achieve not just tomorrow but in the next 6, 12, or even 18 months.
Many companies we talk to think about data quality within specific aspects of their data infrastructure, as opposed to end to end. To solve data quality issues in a specific section of the pipeline (i.e., the transformation or modeling layer), data engineers write a few tests to solve for an immediate and well-understood pain point that their team is currently facing.
While this approach might work short term, it fails organizations when writing, deploying, and maintaining tests becomes a full-time job for a data engineer. And it begs the question, is this really the best use of your data engineer’s time?
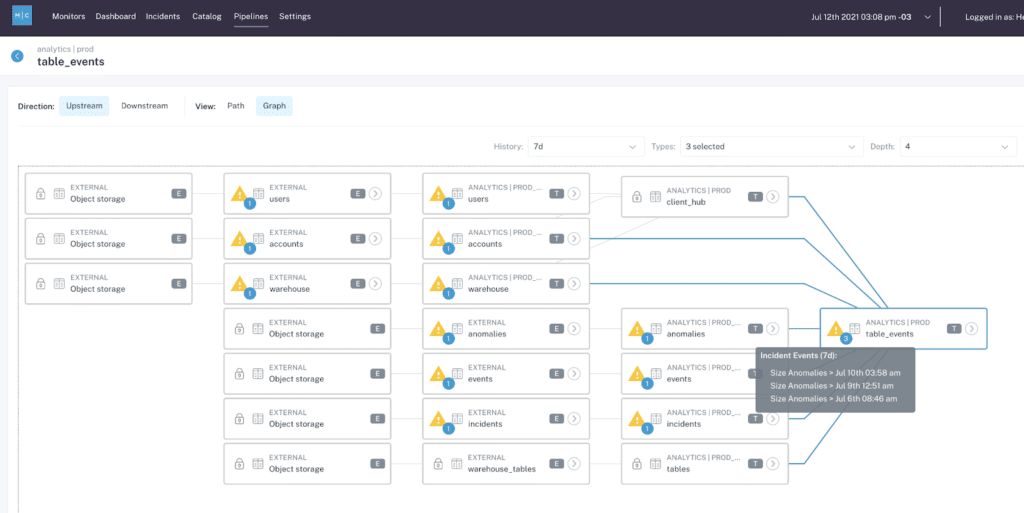
Here’s a checklist of key questions you should be able to answer before deciding whether it makes sense to build your data quality solution in-house or go with a managed vendor:
Who will be the primary user of this data quality solution?
Will this tool be used by data engineers? Or data scientists? What about data analysts? Before you answer these questions, it helps to understand who owns data quality in your organization, and by that we mean: who will be responsible for resolving and reporting on data issues when pipelines break or dashboards go stale? If 15+ data engineers attuned to the specific requirements and behavior of your data are the primary users, building in-house may make the most sense. If you’re working with a broad swath of data personas or support a lean team of engineers and/or analysts, buying a data quality solution with a user-friendly, collaborative interface may be the way to go.
Another benefit to using a SasS solution is that it acts as a single source of truth for data health. In a lot of organizations I speak with, data engineers, analysts, and scientists all have their own data quality processes, resulting in multiple alerts for data incidents, with no single UI to tie everything together.
What data problems do you want your data quality solution to solve?
When an internal build might be the ticket
Are these data problems specific to your business? Is this type of data downtime something that a third-party vendor might not prioritize? If this is the case then it might be best to build on top of an open source solution.
However, if you do take this path, I recommend close alignment between your data engineering and data analytics teams. When it comes to building in-house, communication is key to ensuring that duplications don’t arise across separate parts of the organization. Time and again, I’ve seen data engineering teams build out a monitoring tool for their ETL pipelines, while the analytics team (working just a few cubicles or Zoom calls away) build out a data quality dashboard. Each solution took hundreds of hours and handfuls of team members to build, but only solved specific, short-term problems instead of tackling data quality more strategically from both the analyst and engineering sides of the data stack.
When a third party vendor might be the best choice
Is the problem common in your industry? In this case, a best-in-class SaaS solution would be your best bet as their data quality solution will act as a single source of truth for your data and can support future use cases without any additional investments for your team, assuming the vendor you’re partnering with continues to invest in a customer-centric product roadmap.
What are your data governance requirements?
Data regulations such as CCPA and GDPR have changed the way that businesses handle personal identifiable information (PII). Some companies build their own data catalogs to ensure compliance with state, country, and even economic union regulations.
Regardless of whether you choose to build or buy your data quality solution, governance will be a key consideration, and you should ensure that your solution can meet the needs of your business, particularly if an IPO or any other major company milestone is on the horizon. Note: If you choose to go the route of a third-party vendor, it is important to make sure you invest in options that are SOC 2 certified. You’ll thank us later.
Build or buy a data quality solution? The choice is yours
While there isn’t a magic formula that tells you whether to build or buy a data quality solution, taking stock of who is using your product, the maturity of your data organization, and your data goals can reveal some telling signs.
Until then, here’s wishing you no data downtime!
Interested in learning more about how data teams at Fox, Intuit, and PagerDuty achieve better data quality with Monte Carlo? Reach out to Stephen Guerguy, Scott O’Leary, and book a time to speak with us using the form below..
Our promise: we will show you the product.
Read more posts.