Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is a Data Mesh — and How Not to Mesh it Up

Lior Gavish
CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.

Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Ask anyone in the data industry what’s hot these days and chances are “data mesh” will rise to the top of the list. But what is a data mesh and why should you build one? Inquiring minds want to know.
In the age of self-service business intelligence, nearly every company considers themselves a data-first company, but not every company is treating their data architecture with the level of democratization and scalability it deserves.
Your company, for one, views data as a driver of innovation. Your boss was one of the first in the industry to see the potential in Snowflake and Looker. Or maybe your CDO spearheaded a cross-functional initiative to educate teams on data management best practices and your CTO invested in a data engineering group. Most of all, however, your entire data team wishes there were an easier way to manage the growing needs of your organization, from fielding the never-ending stream of ad hoc queries to wrangling disparate data sources through a central ETL pipeline.
Underpinning this desire for democratization and scalability is the realization that your current data architecture (in many cases, a siloed data warehouse or a data lake with some limited real-time streaming capabilities) may not be meeting your needs.
Fortunately, teams seeking a new lease on data need look no further than a data mesh, an architecture paradigm that’s taking the industry by storm.
Table of Contents
What is a data mesh?
Much in the same way that software engineering teams transitioned from monolithic applications to microservice architectures, the data mesh is, in many ways, the data platform version of microservices.
As first defined by Zhamak Dehghani in 2019, a ThoughtWorks consultant and the original architect of the term, a data mesh is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design. Borrowing Eric Evans’ theory of domain-driven design, a flexible, scalable software development paradigm that matches the structure and language of your code with its corresponding business domain.
Unlike traditional monolithic data infrastructures that handle the consumption, storage, transformation, and output of data in one central data lake, a data mesh supports distributed, domain-specific data consumers and views “data-as-a-product,” with each domain handling their own data pipelines.
Importantly and somewhat controversially, this means according to traditional data mesh principles, the domain teams own the underlying platform or data storage layer. The tissue connecting these domains and their associated data assets is a universal interoperability layer that applies the same syntax and data standards. This can result in some infrastructure duplication, however some teams have adopted “data meshy” structures with platform teams owning a more centralized platform.
Data mesh is often confused with the similar term data fabric (apparently all data analogies must be in the oil or clothing arenas), which was introduced by a Forrester analyst around the start of the millennium. A data fabric is essentially all the various heterogeneous solutions comprising a modern data platform (or modern data stack) tied together by a virtual management layer. It does not have the same emphasis on decentralization and domain driven architecture as data mesh.
Instead of reinventing Zhamak’s very thoughtfully built wheel, we’ll boil down the definition of a data mesh to a few key concepts and highlight how it differs from traditional data architectures.
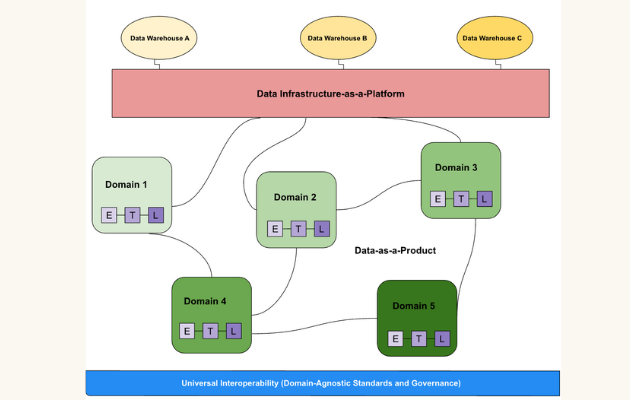
At a high level, here is a data mesh example:
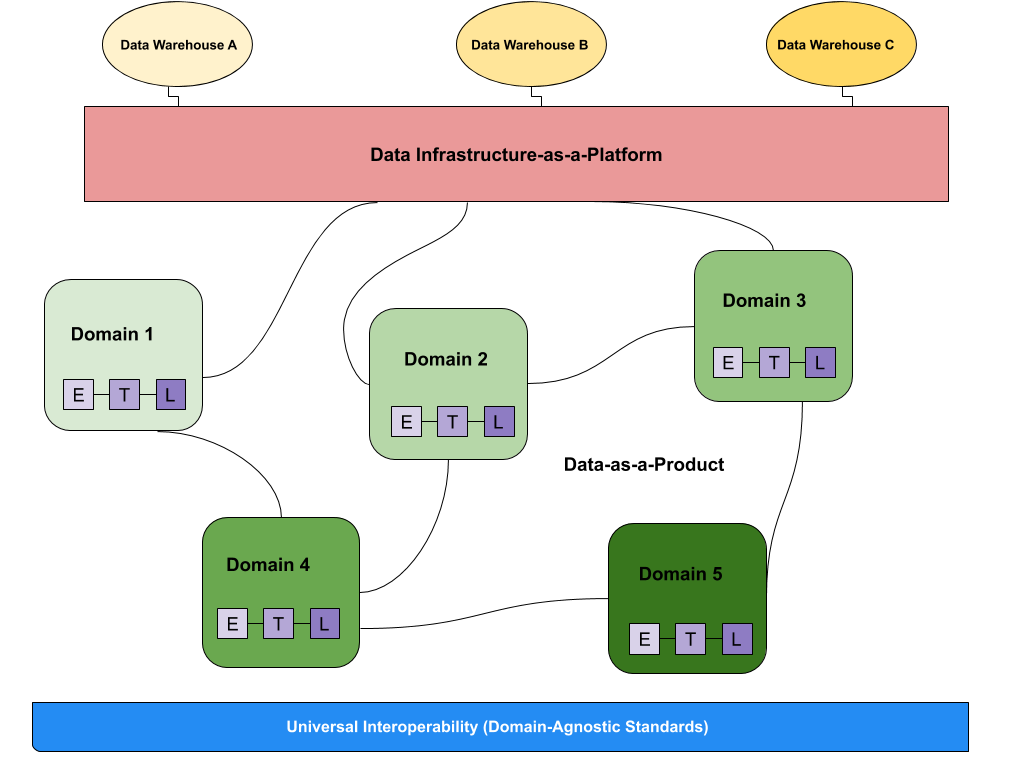
(If you haven’t already, however, I highly recommend reading her groundbreaking article, How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, or watching Max Schulte’s tech talk on why Zalando transitioned to a data mesh. You will not regret it).
Domain-oriented data owners and pipelines
Data meshes federate data ownership among domain data owners who are held accountable for providing their data as products, while also facilitating communication between distributed data across different locations.
While the data infrastructure is responsible for providing each domain with the solutions with which to process it, domains are tasked with managing ingestion, cleaning, and aggregation to the data to generate assets that can be used by business intelligence applications. Each domain is responsible for owning their ETL pipelines, but a set of capabilities applied to all domains that stores, catalogs, and maintains access controls for the raw data. Once data has been served to and transformed by a given domain, the domain owners can then leverage the data for their analytics or operational needs. Data lineage can help data leaders understand consumption patters across their organization and help them transition toward a more decentralized structure.
Self-serve functionality
Data meshes leverage principles of domain-oriented design to deliver a self-serve data platform that allows users to abstract the technical complexity and focus on their individual data use cases.
As outlined by Zhamak, one of the main concerns of domain-oriented design is the duplication of efforts and skills needed to maintain data pipelines and infrastructure in each domain. To address this, the data mesh gleans and extracts domain-agnostic data infrastructure capabilities into a central platform that handles the data pipeline engines, storage, and streaming infrastructure. Meanwhile, each domain is responsible for leveraging these components to run custom ETL pipelines, giving them the support necessary to easily serve their data as well as the autonomy required to truly own the process.
Interoperability and standardization of communications
Underlying each domain is a universal set of data standards that helps facilitate collaboration between domains when necessary — and it often is. It’s inevitable that some data (both raw sources and cleaned, transformed, and served data sets) will be valuable to more than one domain. To enable cross-domain collaboration, the data mesh must standardize on formatting, governance, discoverability, and metadata fields, among other data features. Moreover, much like an individual microservice, each data domain must define and agree on SLAs and quality measures that they will “guarantee” to its consumers.
Why use a data mesh?
Until recently, many companies leveraged a single data warehouse connected to myriad business intelligence platforms. Such solutions were maintained by a small group of specialists and frequently burdened by significant technical debt.
Today, the architecture du jour is a data lake with real-time data availability and stream processing, with the goal of ingesting, enriching, transforming, and serving data from a centralized data platform. For many organizations, this type of architecture falls short in a few ways:
- A central ETL pipeline gives teams less control over increasing volumes of data
- As every company becomes a data company, different data use cases require different types of transformations, putting a heavy load on the central platform
Such data lakes lead to disconnected data producers, impatient data consumers, and worse of all, a backlogged data team struggling to keep pace with the demands of the business. Instead, domain-oriented data architectures, like data meshes, give teams the best of both worlds: a centralized database (or a distributed data lake) with domains (or business areas) responsible for handling their own pipelines. As Zhamak argues, data architectures can be most easily scaled by being broken down into smaller, domain-oriented components.
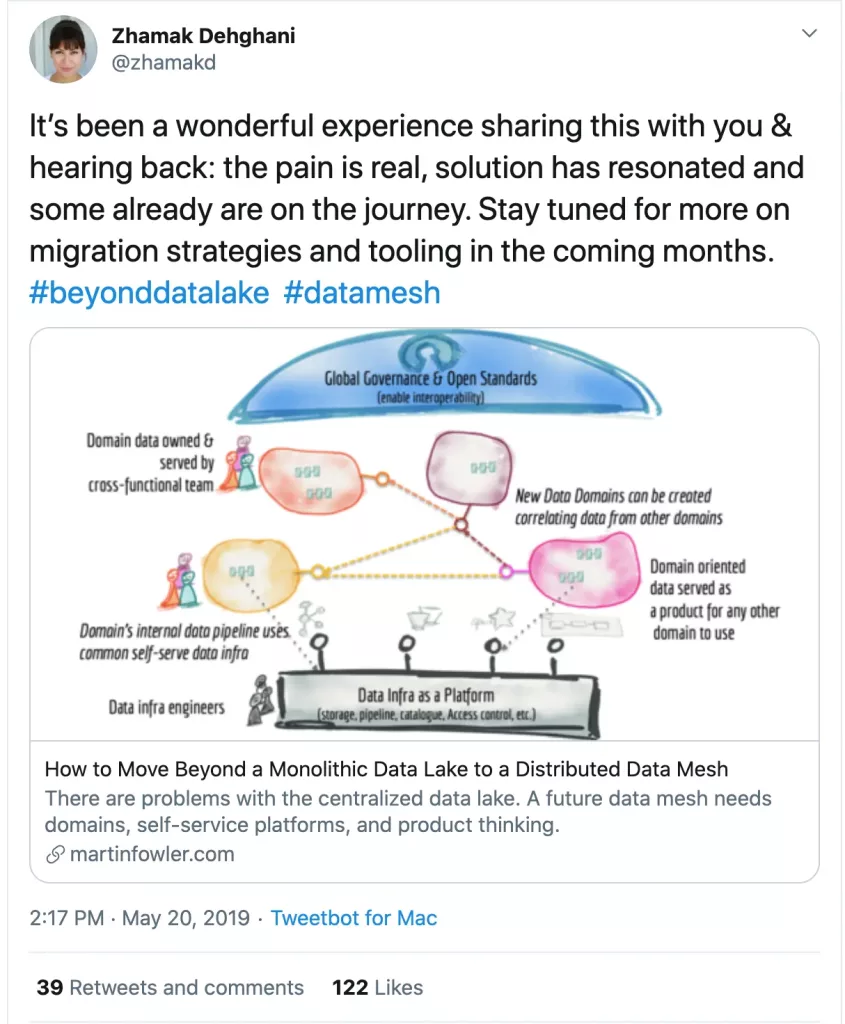
Data meshes provide a solution to the shortcomings of data lakes by allowing greater autonomy and flexibility for data owners, facilitating greater data experimentation and innovation while lessening the burden on data teams to field the needs of every data consumer through a single pipeline.
Meanwhile, the data meshes’ self-serve infrastructure-as-a-platform provides data teams with a universal, domain-agnostic, and often automated approach to data standardization, data product lineage, data product monitoring, alerting, logging, and data product quality metrics (in other words, data collection and sharing). Taken together, these benefits provide a competitive edge compared to traditional data architectures, which are often hamstrung by the lack of data standardization between both ingestors and consumers.
To mesh or not to mesh: that is the question
Teams handling a large amount of data sources and a need to experiment with data (in other words, transform data at a rapid rate) would be wise to consider leveraging a data mesh.
We put together a simple calculation to determine if it makes sense for your organization to invest in a data mesh. Please answer each questions, below, with a number and add them all together for a total, in other words, your data mesh score.
- Quantity of data sources. How many data sources does your company have?
- Size of your data team. How many data analysts, data engineers, and product managers (if any) do you have on your data team?
- Number of data domains. How many functional teams (marketing, sales, operations, etc.) rely on your data sources to drive decision making, how many products does your company have, and how many data-driven features are being built? Add the total.
- Data engineering bottlenecks. How frequently is the data engineering team a bottleneck to the implementation of new data products on a scale of 1 to 10, with 1 being “never” and 10 being “always” ?
- Data governance. How much of a priority is data governance for your organization on a scale of 1 to 10, with 1 being “I could care less” and 10 being “it keeps me up all night”?
Data mesh score
In general, the higher your score, the more complex and demanding your company’s data infrastructure requirements are, and in turn, the more likely your organization is to benefit from a data mesh. If you scored above a 10, then implementing some data mesh best practices probably makes sense for your company. If you scored above a 30, then your organization is in the data mesh sweet spot, and you would be wise to join the data revolution.
Here’s how to break down your score:
- 1–15: Given the size and unidimensionality of your data ecosystem, you may not need a data mesh.
- 15–30: Your organization is maturing rapidly, and may even be at a crossroads in terms of really being able to lean into data. We strongly suggest incorporating some data mesh best practices and concepts so that a later migration might be easier.
- 30 or above: Your data organization is an innovation driver for your company, and a data mesh will support any ongoing or future initiatives to democratize data and provide self-service analytics across the enterprise.
As data becomes more ubiquitous and the demands of data consumers continue to diversify, we anticipate that data meshes will become increasingly common for cloud-based companies with over 300 employees.

How to implement data mesh
Data mesh is not so much an evolution as it’s an overhaul of the technology, people, and processes across the data team. With such an ambitious scope, it can be hard to know where to start.
We asked four data leaders who have successfully implemented data mesh for their advice. The full video can be accessed above, but in summary they advised:
- Choose the right pilot project: Working with one team at first gives you a chance to learn valuable lessons for how to implement data mesh that will be essential as you adopt the architecture across your organization over time. For the pilot project, focus on a data product that has clear, quantifiable business value. There’s no point selecting a data product that has unclear demand or value. However, don’t get too ambitious either. It’s probably a good idea to avoid a pilot that overhauls critical financial reporting.
- Don’t wait on the perfect platform: Think of how to implement data mesh as though you’re remodeling a house while you’re living in it. Instead of demolishing the existing structure and starting from the ground up, you want to go room-by-room and update your data architecture incrementally, highlighting the golden pathways for domain teams to follow.
- Define self-service for yourself: Defining what domain-oriented architecture and self-service data infrastructure look like in your organization all depend on your business needs.For example, one organization provided self-service by helping data producers ingest data through Fivetran. Another made the top priority giving domains control over who could access data and simplified data visualization standards.
- Define domains to thrive independently: Typically, there will remain some cross-domain or shared-domain data that will continue to be managed centrally, often within the data platform team, serving enterprise use cases that cut across two or more domains. Once you have those domains determined, staff the domain teams with the relevant cross-functional talent and domain expertise to thrive on their own
- Focus on building trustworthy data products: Typically, we’ve seen data organizations favor clear standards over heavy governance frameworks, with an emphasis on trustworthy and discoverable data products.
Don’t forget data observability
The vast potential of using a data mesh architecture is simultaneously exciting and intimidating for many in the data industry. In fact, some of our customers worry that the unforeseen autonomy and democratization of a data mesh introduces new risks related to data discovery and health, as well as data management.
Given the relative novelty around data meshes, this is a fair concern, but I would encourage inquiring minds to read the fine print. Instead of introducing these risks, a data mesh actually mandates scalable, self-serve observability into your data.
In fact, domains cannot truly own their data if they don’t have data observability. According to Zhamak, such self-serve capabilities inherent to any good data mesh include:
- Encryption for data at rest and in motion
- Data product versioning
- Data product schema
- Data product discovery, catalog registration, and publishing
- Data governance and standardization
- Data production lineage
- Data product monitoring, alerting, and logging
- Data product quality metrics
When packaged together, these functionalities and standardizations provide a robust layer of observability. The data mesh paradigm also prescribes having a standardized, scalable way for individual domains to handle these various tenants of observability, allowing teams to answer these questions and many more:
- Is my data fresh?
- Is my data broken?
- How do I track schema changes?
- What are the upstream and downstream dependencies of my pipelines?
If you can answer these questions, you can rest assured that your data is fully observable — and can be trusted.
The (near) future of data mesh
Data mesh creator Zhamak Dehghani just set the data world abuzz with her announcement of her long-anticipated startup nextdata, “designed to empower data developers, users and owners with a delightful experience where data products are a first-class primitive, with trust built-in.”
Data mesh continues to be hot with our CEO Barr projecting it to be one of the 10 hottest data engineering trends in 2023. It will be interesting to see how teams balance implementing a fully decentralized data mesh versus architectures that still contain some sort of center of excellence.
Interested in learning more about the data mesh? In addition to Zhamak and Max’s resources, check out some of our favorite articles about this rising star of data engineering:
- Data Mesh Applied — Sven Balnojan
- The Data Mesh: Re-Thinking Data Integration — Kevin Petrie
- Should Your Application Consider Data Mesh Connectivity? — Joe Gleinser
Is your company building a data mesh? Reach out Barr Moses and Lior Gavish with your experiences, tips, and pain points. We’d love to hear from you! Or book a time to speak with us below.
Our promise: we will show you the product.
Frequently Asked Questions
What is a data mesh in simple terms?
A data mesh is a concept for creating decentralized data teams that operate within each business department (or domain). Rather than focusing on a main source of truth, data products are created to solve specific use cases with a focus on interoperability.
What is a data mesh example?
Imagine if instead of an IT department there were marketing IT specialists or HR IT specialists that focused on creating solutions for the specific needs of those business users rather than emphasizing a core set of shared services. Replace IT with data teams and that explains the core concept of data mesh.
What is the difference between a data lake and data mesh?
A data lake is a type of technology where unstructured data is stored and processed. A data mesh is a set of organizational principles that emphasize decentralized teams, federated governance, treating data like a product, and enabling self-service access to data.
Read more posts.